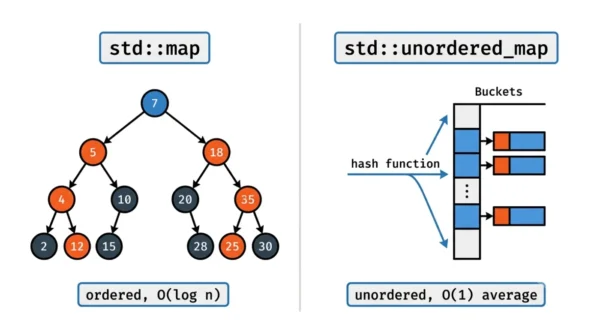
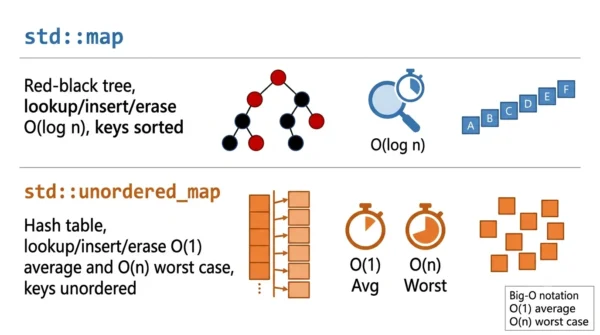
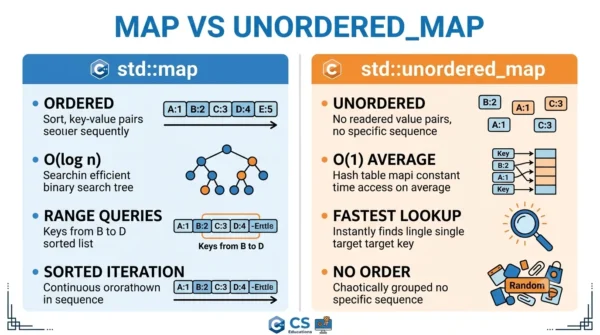
std::map is an ordered container built on a self-balancing binary search tree, so it keeps keys sorted and runs every operation in O(log n). std::unordered_map is a hash table, so it keeps no order but runs operations in O(1) on average. Pick unordered_map for the fastest average lookups, and map when you need sorted keys or range queries.
In C++, map vs unordered_map is one of the most common container choices, and it comes up constantly in interviews and competitive programming. Both store key-value pairs with unique keys, so they look interchangeable until performance or ordering matters.
The difference comes from what sits underneath. One is a balanced tree that keeps keys sorted; the other is a hash table that trades order for speed. That single choice decides their complexity, memory use, and iteration order.
This guide defines each container, compares them point by point, digs into time complexity and memory, and shows when to reach for which. Both are part of the C++ Standard Template Library.
What is std::map?
std::map is an ordered associative container that stores key-value pairs with unique keys. It is implemented as a self-balancing binary search tree, almost always a red-black tree. Because of that tree, the keys are always kept in sorted order.
Every core operation, such as lookup, insertion, and deletion, runs in O(log n), guaranteed. Iterating a map visits keys in ascending order, and it supports ordered operations like lower_bound, upper_bound, and range queries. The key type only needs a comparison (operator<).
The trade-off is speed: O(log n) is slower than a hash lookup, and the scattered tree nodes are not cache-friendly. You choose map when order is worth that cost.
What is std::unordered_map?
std::unordered_map, added in C++11, stores the same key-value pairs but is built on a hash table. A hash function maps each key to a bucket, so the container keeps no order at all.
That hashing makes lookup, insertion, and deletion run in O(1) on average. The catch is the worst case: with many hash collisions or a rehash, an operation can degrade to O(n). Iteration visits elements in an unspecified order, and the key type needs both a hash function and operator==.
It usually uses more memory than a map, because it keeps an array of buckets plus the nodes. You choose unordered_map when you want the fastest average lookups and do not care about order.
map vs unordered_map: Key Differences
| Aspect | std::map | std::unordered_map |
|---|---|---|
| Underlying structure | Self-balancing BST (red-black tree) | Hash table |
| Ordering | Keys sorted in ascending order | No order (arbitrary) |
| Lookup / insert / erase | O(log n) guaranteed | O(1) average, O(n) worst case |
| Iteration order | Sorted by key | Unspecified |
| Memory use | Lower; node + tree pointers | Higher; bucket array + nodes |
| Key requirement | Comparison (operator<) | Hash function + operator== |
| Ordered operations | Yes (lower_bound, range queries) | No |
| Worst case | O(log n), predictable | O(n) on heavy collisions / rehash |
| Introduced in | C++98 | C++11 |
| Best for | Sorted data, range queries | Fastest average lookups |
Time Complexity and Memory
The complexity gap is the heart of the comparison. std::map guarantees O(log n) for lookup, insert, and erase, because a red-black tree stays balanced. The performance is predictable no matter the data.
std::unordered_map averages O(1) for the same operations, which is why it usually wins on raw lookup speed. Its O(n) worst case only appears with poor hashing or a rehash, and a good hash function makes that rare. For the bigger picture on how structure choice drives speed, see our guide to the time complexity of data structures.
Memory differs too. A map stores a few pointers and a colour bit per node, while an unordered_map keeps a bucket array on top of its nodes, so it generally uses more memory. For small collections the difference is minor; for large ones, profile before assuming.
Code Examples
Both containers share almost the same interface, so the code looks similar. The behaviour differs in ordering and speed.
std::map — sorted keys:
#include <map>
#include <iostream>
std::map<std::string, int> m;
m["banana"] = 5;
m["apple"] = 3;
// Iterates in SORTED key order: apple, banana
for (const auto& [key, val] : m)
std::cout << key << ": " << val << "\n";std::unordered_map — fast, unordered:
#include <unordered_map>
#include <iostream>
std::unordered_map<std::string, int> um;
um["banana"] = 5;
um["apple"] = 3;
// O(1) average lookup; iteration order is UNSPECIFIED
std::cout << um["apple"] << "\n"; // 3Swap map for unordered_map and the program still compiles, but the iteration order changes and lookups get faster on average. That drop-in similarity is exactly why the choice is so easy to get wrong.
When to Use map vs unordered_map
Use std::unordered_map as the default when you just need fast key-value lookups and order does not matter. Counting frequencies, caching, and de-duplication all fit it well, and its average O(1) speed is hard to beat.
Use std::map when order is part of the problem. If you need keys sorted, range queries with lower_bound and upper_bound, or an in-order traversal, the tree gives you that for free. It is also the safer pick when you need a guaranteed worst case rather than an average.
One more practical note. For very small maps, the two perform almost the same, so readability wins. For large, lookup-heavy workloads, unordered_map usually pulls ahead, but always profile your real data before committing.
Interview Questions on map vs unordered_map
std::map is built on a self-balancing binary search tree, almost always a red-black tree, which keeps keys sorted and gives O(log n) operations. std::unordered_map is built on a hash table, which gives O(1) average operations but no ordering. The data structure explains every other difference.unordered_map is faster on average because of O(1) hashing, but its worst case is O(n) under heavy collisions or a rehash, while map guarantees O(log n). For very small containers the difference is negligible, and when you need sorted order or range queries, map is the better choice despite being slower per lookup.map when you need keys in sorted order, ordered iteration, or range queries through lower_bound and upper_bound. It is also better when you need a predictable O(log n) worst case, or when the key type has a natural ordering but no good hash function.Frequently Asked Questions
std::map is an ordered container built on a red-black tree, so keys stay sorted and operations run in O(log n). std::unordered_map is built on a hash table, so it keeps no order and operations run in O(1) on average. Use map for sorted keys and range queries, and unordered_map for the fastest average lookups.unordered_map does O(1) hashed lookups, while map does O(log n) tree lookups. But unordered_map can drop to O(n) in the worst case, and for small containers the two are about equal. Profile real data before assuming one is faster.map performs lookup, insertion, and deletion in O(log n) in all cases. unordered_map performs them in O(1) on average and O(n) in the worst case, when many keys collide or the table rehashes. Both use O(n) space.unordered_map stores keys by hash, so iteration order is unspecified and can change as elements are added. If you need keys in sorted order or need to iterate in order, use std::map, which keeps keys sorted at all times.Wrapping Up
The whole comparison comes down to the structure beneath each container. std::map is a sorted tree with guaranteed O(log n) operations, and std::unordered_map is a hash table with O(1) average operations and no order.
So ask one question: do you need the keys in order? If yes, reach for map and its range queries. If no, reach for unordered_map and its faster average lookups, then profile if performance is critical.
Related reading on DiffStudy:
- Time Complexity of Data Structures
- HashMap vs Hashtable
- Binary Tree vs Binary Search Tree
- CS Fundamentals hub