MLOps vs DevOps is the pivotal architectural question for every engineering organization adopting artificial intelligence in 2026 — and most teams are still trying to answer it by forcing machine learning workflows into pipelines designed for traditional software. The result is predictable: 55% of machine learning models never reach production, and the majority that do degrade silently as the real-world data they were trained on shifts away from their training distribution. DevOps transformed software delivery by automating the path from code commit to production deployment.
MLOps extends that transformation to the fundamentally different lifecycle of machine learning models — where data versioning, experiment tracking, model validation, feature stores, drift detection, and automated retraining are as essential as build scripts and deployment manifests. The MLOps market reflects the urgency: valued at $3.4 billion in 2026 and projected to reach $25.93 billion by 2034 at a 28.9% CAGR, it is one of the fastest-growing segments in enterprise software, driven by a single reality — getting a model into production is only 20% of the challenge of running ML at scale. The other 80% is keeping it working. Whether you are a data scientist struggling to get models deployed, a DevOps engineer being asked to support ML workloads, an engineering manager building an AI team, or a student learning the modern ML engineering stack — this MLOps vs DevOps comparison gives you the complete picture of what separates these disciplines, where they overlap, and how to build a delivery infrastructure that serves both.
MLOps vs DevOps: The AI Delivery Landscape in 2026
The MLOps vs DevOps distinction has never mattered more. DevOps reached near-universal adoption — 78% of organizations globally practice it, and Fortune 500 companies report 90% DevOps adoption. But as those same organizations rush to deploy machine learning models, they are discovering that CI/CD pipelines designed for deterministic software behave poorly against probabilistic, data-dependent systems that degrade over time in ways no unit test can catch. MLOps emerged as the answer: a discipline that applies DevOps automation principles to the unique challenges of machine learning — data versioning, experiment tracking, model registries, drift monitoring, and automated retraining pipelines — while bridging the cultural gap between data scientists, ML engineers, and operations teams.
MLOps vs DevOps: The DevOps Foundation
Definition
DevOps is a culture, methodology, and toolchain that integrates software development (Dev) and IT operations (Ops) into a continuous, automated delivery lifecycle. It removes the silos between the teams that write code and the teams that run systems — replacing slow, error-prone manual handoffs with automated CI/CD pipelines, infrastructure as code, continuous testing, and shared operational ownership. The core loop of DevOps is deterministic: code is written, committed, built, tested, packaged, deployed, and monitored. When all tests pass, the same artifact deployed to staging is what reaches production. DevOps works exceptionally well for this kind of software because the artifact itself does not change in production — a compiled binary or container image behaves exactly as it was tested. In the MLOps vs DevOps comparison, this determinism is the key difference: DevOps assumes that what you deploy stays correct until you change it. ML models do not make that guarantee.
Strengths and Advantages
- Mature tooling ecosystem: 15+ years of CI/CD tooling, container orchestration, IaC, and observability platforms — Jenkins, GitHub Actions, Docker, Kubernetes, and Terraform are battle-tested at massive scale
- Deterministic delivery: Code artifacts behave the same way in every environment — automated tests provide high confidence that what ships is what was validated, enabling reliable high-frequency deployments
- Fast feedback loops: Automated test suites, deployment pipelines, and production monitoring give teams rapid feedback from commit to production, enabling iteration cycles measured in hours rather than weeks
- Universal skills availability: DevOps engineers are widely available, certification paths are well-established, and toolchain knowledge transfers across organizations and industries
- Strong cultural foundation: DevOps collaboration practices — blameless post-mortems, shared on-call, cross-functional teams — provide the cultural infrastructure that MLOps teams build on
- Cloud-native fit: DevOps practices align tightly with cloud-native architectures — containers, microservices, serverless, and Kubernetes all have deep DevOps tooling support
Limitations for ML Workloads
- No concept of model drift: DevOps pipelines have no mechanism for detecting that a deployed model’s prediction accuracy has degraded as real-world data distributions shift — a problem unique to ML systems
- No data versioning: Standard DevOps tools version code, not datasets — training data is the most critical artifact in ML, and without versioning it, experiments are impossible to reproduce reliably
- No experiment tracking: DevOps pipelines do not capture hyperparameters, training metrics, or model performance across experimental runs — data scientists lose the context needed to understand why one model outperforms another
- No model registry: DevOps artifact registries (Docker Hub, Nexus) store code artifacts, not models with associated metadata, lineage, performance benchmarks, and approval workflows
- Retraining blind spot: DevOps CD pipelines deploy on code changes — they have no trigger mechanism for model retraining when data drift is detected or when model accuracy falls below a threshold
- Role gap: DevOps bridges Dev and Ops — but ML delivery requires data scientists, data engineers, ML engineers, and MLOps platform engineers, none of which map cleanly to standard DevOps team roles
DevOps Core Technical Parameters:
Pipeline Artifact: Code → compiled binary, container image, or deployment package — deterministic, reproducible given the same source input. Testing Model: Unit, integration, and end-to-end tests validate functional correctness — pass/fail gates are binary and stable. Deployment Trigger: Code commit or tag — deployment initiated by human-driven source changes. Furthermore, Production Monitoring: Uptime, latency, error rates, throughput — infrastructure and application health metrics. Additionally, Team Roles: Developers, DevOps engineers, SREs, platform engineers — all with deep software and systems expertise. Moreover, Versioning Scope: Source code, configuration, infrastructure — managed via Git and IaC tooling.
MLOps vs DevOps: What MLOps Adds
Definition
MLOps — Machine Learning Operations — is the discipline that applies DevOps principles to the unique lifecycle of machine learning models, extending CI/CD automation to cover data management, experiment tracking, model training, evaluation, registration, deployment, and continuous model monitoring. Coined by Databricks and formalized as a practice around 2018–2019, MLOps bridges the gap between data scientists who build models and engineering teams who operationalize them — the gap responsible for the 55% production failure rate of ML projects. In the MLOps vs DevOps framework, the fundamental distinction is that ML models are not static software artifacts. A model trained on last quarter’s data may be less accurate today because fraud patterns evolved, customer behavior shifted, or supply chain dynamics changed — and no code commit triggered that degradation. MLOps introduces the feedback loops, monitoring systems, and automation infrastructure that detect this drift and initiate corrective retraining without human intervention. MLOps encompasses three maturity levels: manual ML (data scientists running Jupyter notebooks and deploying models manually), automated ML pipeline (automated training and deployment triggered by code or data changes), and fully automated MLOps (CI/CD/CT — continuous training — with drift detection, automatic retraining, and human-in-the-loop approval gates for model promotion).
Strengths and Advantages
- Production deployment success: Organizations with mature MLOps practices deploy models 6x faster and achieve significantly higher production deployment success rates than those relying on ad-hoc DevOps pipelines for ML workloads
- Drift detection and automated retraining: Continuous monitoring detects data drift and concept drift, triggering automated retraining pipelines that keep models accurate without manual intervention — hours vs. months of detection latency
- Experiment reproducibility: Data versioning (DVC), experiment tracking (MLflow, Weights & Biases), and model registries create full lineage from training data through model artifact to production deployment — essential for regulated industries and model governance
- Feature store efficiency: Centralized feature stores share engineered features across models and teams — reducing duplicate feature engineering work by up to 40% and ensuring training/serving feature consistency
- Model governance and compliance: Model registries with approval workflows, model cards, bias metrics, and explainability documentation address the AI governance requirements of GDPR, EU AI Act, and financial services regulations
- Scalable AI organization: MLOps platforms enable data science teams to manage dozens or hundreds of models in production — impossible with manual or ad-hoc DevOps approaches at that scale
Challenges and Limitations
- Talent scarcity: 40% of organizations report shortages of engineers skilled in both ML and DevOps/SRE — the ML engineer role combining data science with systems engineering is one of the most scarce in tech in 2026
- Toolchain complexity: A full MLOps stack spans data versioning, feature stores, experiment trackers, training orchestrators, model registries, serving platforms, and monitoring tools — significantly more complex than a standard DevOps toolchain
- Cultural friction: Data scientists trained in research workflows resist operationalization constraints; DevOps engineers without ML background struggle to understand model-specific monitoring requirements and retraining triggers
- Data infrastructure dependency: MLOps requires reliable, governed data pipelines as a prerequisite — organizations with poor data quality or fragmented data infrastructure cannot build effective MLOps on top of a broken foundation
- Early-stage overhead: Full MLOps platform investment is overkill for teams training one or two models — the infrastructure cost and complexity only pays off at the scale of multiple models in production requiring continuous management
- Evolving standards: The MLOps tooling landscape is fragmented and rapidly changing — standardization around platforms, APIs, and practices is still maturing compared to the stable DevOps ecosystem
MLOps Core Technical Parameters:
Pipeline Artifact: Trained model artifact with associated metadata — weights, hyperparameters, training data reference, performance metrics, and lineage. Data Versioning: DVC (Data Version Control) or cloud-native equivalents track dataset versions alongside model versions for full reproducibility. Experiment Tracking: MLflow, Weights & Biases, or Comet ML log hyperparameters, metrics, and artifacts across training runs — enabling comparison and reproducibility. Furthermore, Model Registry: Centralized catalog of versioned models with staging/production promotion workflows, performance benchmarks, and governance metadata. Additionally, Drift Monitoring: Statistical tests (KS test, PSI, MMD) detect data distribution shifts and model prediction degradation — triggering automated retraining when thresholds are crossed. Moreover, Serving Infrastructure: Real-time inference (REST API, gRPC), batch prediction, A/B testing, and shadow deployment for safe model rollouts — managed via platforms like KServe, BentoML, Seldon, or SageMaker endpoints.
MLOps vs DevOps: Pipeline Architecture Deep Dive
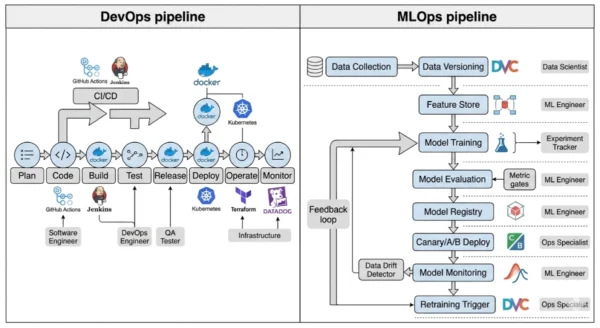
DevOps Pipeline Architecture
- Source control: Git repository holds all code — version control is the single source of truth for what gets deployed
- CI trigger: Code commit or pull request triggers automated build and test pipeline immediately
- Build stage: Compiles code, runs linters, builds Docker image or deployment artifact — deterministic output from deterministic input
- Test stage: Unit, integration, and end-to-end tests validate functional correctness — pass/fail gates are stable
- Artifact registry: Docker Hub, Nexus, or cloud container registry stores the deployment artifact with version tag
- Deploy stage: CD pipeline pushes artifact to staging then production — rolling, blue-green, or canary deployment strategies
- Monitor stage: APM, logging, and alerting tools monitor uptime, latency, error rates, and throughput
- Feedback loop: Production incidents trigger tickets or PagerDuty alerts — engineers investigate and push code fixes
MLOps Pipeline Architecture
- Data pipeline: Automated data ingestion, validation (Great Expectations), and versioning (DVC) — data is a first-class versioned artifact alongside code
- Feature store: Centralized feature engineering and serving (Feast, Tecton, Vertex AI Feature Store) — ensures training and serving use identical feature transformations
- Experiment tracking: Training runs logged with hyperparameters, metrics, and artifacts in MLflow or W&B — enables reproducibility and comparison
- Model evaluation gate: Automated evaluation against holdout datasets — model only progresses if it meets accuracy, latency, fairness, and bias thresholds
- Model registry: MLflow Model Registry, Vertex AI, or SageMaker Model Registry — staged promotion (Staging → Production) with approval workflows
- Model serving: Real-time inference API, batch prediction, or streaming — A/B testing and shadow mode deployment for safe rollout
- Model monitoring: Data drift, concept drift, prediction drift, and feature distribution monitoring — statistical tests running continuously in production
- Retraining trigger: Drift detection, scheduled retraining, or performance degradation alerts trigger automated retraining pipeline — closing the continuous training loop
MLOps vs DevOps: The Maturity Level Spectrum
| Maturity Level | Description | Automation Level | Suitable For |
|---|---|---|---|
| Level 0 — Manual ML | Data scientists use Jupyter notebooks; models deployed manually via scripts or direct API calls | None — entirely manual process, no reproducibility | Prototypes, proof-of-concept projects with one model |
| Level 1 — ML Pipeline Automation | Automated training pipeline triggered by data or code changes; experiment tracking and model registry in place | Automated training and deployment; manual drift monitoring | Small teams with 2–10 models in production |
| Level 2 — CI/CD for ML | Full CI/CD/CT pipeline — code, data, and model changes all trigger automated validation and deployment workflows | High — automated training, validation, deployment, and drift monitoring | Mid-size orgs deploying models at scale, regulated industries |
| Level 3 — Full MLOps | Drift-triggered automatic retraining, model governance, SBOM for models, A/B testing, feature store, full lineage | Near-full automation with human-in-the-loop approval for model promotion only | Enterprise AI organizations, 50+ models, compliance-driven industries |
MLOps vs DevOps: Toolchain Side by Side
| Pipeline Function | DevOps Tooling | MLOps Tooling |
|---|---|---|
| Source control | Git (GitHub, GitLab, Bitbucket) | Git + DVC for data versioning alongside code |
| CI/CD orchestration | Jenkins, GitHub Actions, CircleCI, GitLab CI | Kubeflow Pipelines, Airflow, Prefect, Metaflow, ZenML |
| Artifact registry | Docker Hub, AWS ECR, Nexus, Artifactory | MLflow Model Registry, AWS SageMaker, Vertex AI, Azure ML |
| Testing framework | JUnit, pytest, Selenium, Postman | Great Expectations (data), Deepchecks (model), Evidently (drift) |
| Infrastructure provisioning | Terraform, Pulumi, Ansible, CloudFormation | Terraform + GPU/TPU cluster management, Kubernetes operator for ML |
| Monitoring | Datadog, Prometheus, Grafana, New Relic | Evidently AI, WhyLabs, Arize AI, Fiddler AI, Seldon Alibi |
| Experiment management | Not applicable | MLflow, Weights & Biases, Comet ML, Neptune AI |
| Feature management | Not applicable | Feast, Tecton, Vertex AI Feature Store, Hopsworks |
MLOps vs DevOps: Use Cases and Real-World Scenarios
Where DevOps Alone Is Sufficient
- Traditional software applications: APIs, web applications, microservices, and data pipelines that execute deterministic business logic — DevOps CI/CD is purpose-built for this and requires no MLOps augmentation
- Rule-based automation: Systems using explicit rules, decision trees, or configuration-driven logic rather than learned models — deterministic code tests cover correctness without probabilistic monitoring
- Static ML models with no retraining requirement: A small number of production models with stable, slowly-changing data distributions that are retrained infrequently on a fixed schedule — basic DevOps CD with manual retraining is viable
- Early-stage ML exploration: Teams building their first model, doing proof-of-concept work, or still validating the business case for ML — full MLOps infrastructure investment is premature before production intent is confirmed
- Low-frequency batch ML jobs: Monthly or quarterly batch scoring pipelines with no real-time inference requirement and low cost of delayed retraining — standard scheduled jobs in a DevOps pipeline are adequate
Where MLOps Is Essential
- Real-time ML inference at scale: Fraud detection, recommendation engines, dynamic pricing, and content ranking models serving millions of predictions per day require dedicated serving infrastructure, latency monitoring, and drift detection that DevOps pipelines cannot provide
- Financial services and healthcare ML: Credit scoring, loan underwriting, clinical decision support, and diagnostic models require model explainability, bias monitoring, regulatory audit trails, and governance workflows mandated by financial regulators and HIPAA
- Multi-model production environments: Organizations managing 10+ models in production need centralized registries, standardized deployment workflows, and shared monitoring infrastructure — manual DevOps management does not scale
- Time-sensitive data environments: E-commerce, advertising, and social media models where data distributions shift daily or weekly require automated retraining pipelines — a model trained in January may be significantly less accurate by February without retraining
- LLM and generative AI deployment: Large language model deployments require specialized serving infrastructure (vLLM, TGI, TensorRT-LLM), prompt versioning, evaluation frameworks, and output quality monitoring that extend MLOps into the LLMOps domain
MLOps vs DevOps: Industry Adoption Patterns
| Industry | Primary ML Use Case | MLOps Priority | Key Driver |
|---|---|---|---|
| Financial Services (40% of MLOps market) | Fraud detection, credit scoring, algorithmic trading | Critical — highest adoption segment | Model accuracy = revenue; regulatory explainability mandates |
| Healthcare / Life Sciences | Diagnostics, drug discovery, clinical decision support | Critical — patient safety stakes | FDA AI/ML SaMD guidance, HIPAA, model bias concerns |
| E-commerce / Retail | Recommendation engines, dynamic pricing, demand forecasting | High — revenue directly tied to model accuracy | Data shifts daily; model degradation = lost revenue |
| Technology / SaaS | Search ranking, content moderation, user personalization | High — core product quality | Real-time inference scale, A/B testing culture, fast iteration |
| Manufacturing / Industrial | Predictive maintenance, quality control, supply chain optimization | Medium-High — reliability and safety | Sensor data drift, equipment variation, safety criticality |
| Government / Defense | Surveillance, logistics optimization, document processing | High — emerging regulatory frameworks | EU AI Act, US Executive Order on AI, accountability requirements |
12 Critical Differences: MLOps vs DevOps
The MLOps vs DevOps comparison below covers every key dimension — from pipeline artifacts and testing philosophy to team roles, toolchains, monitoring approach, and production failure characteristics unique to ML systems.
Aspect | DevOps | MLOps |
|---|---|---|
| Primary Artifact | Code — deterministic binary, container image, or deployment package that behaves identically across environments | ML model — probabilistic artifact with weights, hyperparameters, training data reference, and performance metrics that must be versioned together |
| Production Stability | Static — deployed artifact remains correct until a code change is deliberately pushed by engineers | Dynamic — model accuracy degrades over time as real-world data distributions shift, even without any code change |
| Testing Philosophy | Functional correctness — unit tests, integration tests, and end-to-end tests validate deterministic behavior (pass/fail) | Statistical performance — accuracy, precision, recall, AUC, fairness metrics, and data quality tests validate probabilistic model behavior against thresholds |
| Versioning Scope | Source code and configuration — Git tracks all changes that affect system behavior | Code + data + model — DVC or equivalent versions datasets alongside code; model registry versions trained artifacts with full lineage |
| Pipeline Trigger | Code commit — CI/CD pipeline runs when engineers push changes to source control | Code commit OR data change OR drift detection OR scheduled retraining — multiple trigger types reflecting ML’s data dependency |
| Deployment Strategy | Blue-green, rolling, or canary based on traffic routing — feature flags control rollout pace | A/B testing, shadow mode, and canary deployment with statistical significance monitoring — performance metrics compared between model versions before full promotion |
| Production Monitoring | Infrastructure metrics — latency, throughput, error rates, uptime, and resource utilization | Infrastructure metrics PLUS model-specific metrics — data drift, concept drift, prediction distribution shift, feature importance changes, and model accuracy against ground truth labels |
| Failure Detection | Hard failures — service down, exceptions thrown, timeouts, or SLA breaches trigger alerts | Soft failures — model silently returns wrong predictions without error codes; drift detection statistical tests required to catch accuracy degradation |
| Feedback Loop | Production incident → alert → engineer investigates → code fix deployed | Drift detection → retraining trigger → automated training pipeline → model evaluation → registry promotion → deployment — full loop automated in mature MLOps |
| Team Roles | Developers, DevOps engineers, SREs, platform engineers — primarily software and systems expertise | Data scientists, data engineers, ML engineers, MLOps platform engineers, and AI product managers — requires ML, data, and systems expertise simultaneously |
| Toolchain Complexity | Moderate — CI/CD platform, container registry, IaC, APM, logging, and alerting tools | High — adds data versioning, feature store, experiment tracker, training orchestrator, model registry, model serving platform, and drift monitoring tools to the DevOps toolchain |
| Regulatory Considerations | Security and compliance (SOC 2, PCI DSS) — DevSecOps practices address most requirements | AI-specific regulations — EU AI Act, FDA AI/ML SaMD guidance, GDPR model explanation rights, financial model risk management (SR 11-7) all require model cards, bias testing, and explainability documentation |
MLOps vs DevOps: Building Your MLOps Pipeline — Implementation Guide
Phase 1 — Foundation: DevOps for ML (Weeks 1–4)
- Establish code and experiment version control: Migrate Jupyter notebooks to Python scripts or modular code packages tracked in Git. Add DVC for data and model artifact versioning alongside your code repository. This single step — making experiments reproducible — provides immediate value before any other MLOps infrastructure is built.
- Add experiment tracking: Integrate MLflow or Weights & Biases into your training code to log hyperparameters, training metrics, and model artifacts automatically on every training run. A few lines of code per training script creates a searchable history of all experiments — replacing the spreadsheet tracking most teams rely on initially.
- Set up a basic model registry: Use MLflow Model Registry (open source) or your cloud provider’s model registry (SageMaker, Vertex AI, Azure ML) to store trained model versions with stage labels (Staging, Production, Archived) and performance benchmarks. This creates the single source of truth for what model is deployed where.
- Containerize model serving: Package your model serving code in Docker containers — applies DevOps containerization principles to ML inference and makes model deployment to Kubernetes or cloud-managed serving platforms straightforward.
- Add basic CI to training code: Extend your existing CI/CD pipeline to run data validation (Great Expectations) and model evaluation tests on every training code change. This catches regressions in model performance caused by code changes before they reach production.
Phase 2 — Automation: ML Pipeline and CD (Weeks 5–12)
Training Pipeline Automation
- Implement a training pipeline orchestrator — Kubeflow Pipelines, Airflow, Prefect, or Metaflow — that executes data preparation, feature engineering, training, and evaluation as a reproducible, parameterized DAG
- Add automated model evaluation gates — the training pipeline only promotes a model to the registry if it meets predefined accuracy, latency, and fairness thresholds compared to the current production model
- Implement scheduled and trigger-based retraining — configure training pipelines to run on a schedule AND when data drift is detected, ensuring models stay current without manual intervention
- Set up a feature store for high-value features — Feast (open source) or cloud-native equivalents eliminate training/serving skew and enable feature reuse across models, cutting feature engineering time by up to 40%
Model Deployment and Serving
- Implement canary and A/B deployment for model rollouts — route a small percentage of traffic to the new model version and compare performance metrics against the incumbent before full promotion
- Set up shadow mode deployment for high-risk models — the new model runs alongside production receiving the same inputs but without serving its predictions to users, validating behavior before real traffic exposure
- Implement model serving with SLA monitoring — track prediction latency P50/P95/P99, throughput, and error rates alongside model-specific metrics in a unified observability dashboard
- Add prediction logging — store input features and model predictions for every inference (or a sampled fraction at high volume) to enable retrospective drift analysis and ground truth label collection for future retraining
Phase 3 — Mature MLOps: Drift Monitoring and Governance (Months 4–6)
- Deploy drift monitoring: Implement statistical drift detection (Evidently AI, WhyLabs, or Arize AI) to monitor data distribution changes in production input features and model prediction distributions. Configure alerting thresholds and integrate drift detection into the retraining trigger pipeline — the closed-loop CT (continuous training) system that defines mature MLOps.
- Add ground truth feedback collection: For supervised learning models, build pipelines to collect delayed labels from production outcomes (e.g., whether a fraud-flagged transaction was confirmed as fraud) and route them back into training data for future retraining. This closes the model performance measurement loop that drift proxies approximate.
- Implement model governance documentation: Generate model cards for every production model — documenting intended use, performance metrics across demographic groups, known limitations, and training data provenance. Required for EU AI Act compliance in high-risk AI categories and increasingly expected by enterprise customers as part of vendor AI risk assessment.
- Build a model risk review process: Establish a lightweight governance workflow for model promotion from Staging to Production — a model review committee or automated checklist covering bias testing, performance benchmarks, adversarial robustness, and compliance documentation. This creates the audit trail that regulated industries require.
- Scale across teams with shared MLOps platform: Standardize your MLOps toolchain as an internal platform — golden path templates for training pipelines, standard Docker base images for serving, shared feature store access, and centralized model registry with organization-wide visibility. This enables multiple data science teams to follow consistent MLOps practices without reinventing infrastructure independently.
MLOps vs DevOps: Cost, ROI and Team Structure Analysis
ML Production Failure
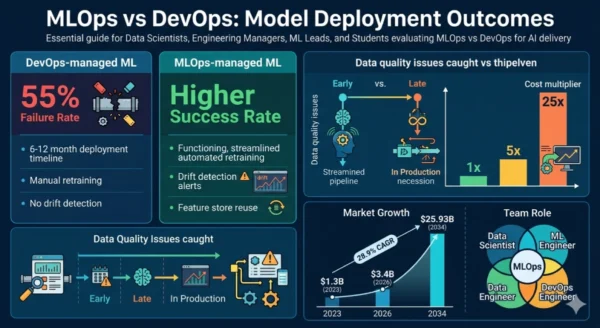
55%
Of ML models never reach production without mature MLOps practices in place
Faster Deployment
6x
Faster model deployment to production for organizations with mature MLOps vs ad-hoc pipelines
Feature Reuse Saving
40%
Reduction in feature engineering time from centralized feature store reuse across teams
Market Growth
28.9%
CAGR of the MLOps market 2026–2034 — from $3.4B to $25.93B
MLOps Toolchain Cost Guide (2026)
| Toolchain Layer | Open Source Option (Free) | Commercial Option | Monthly Cost Estimate |
|---|---|---|---|
| Experiment tracking | MLflow (self-hosted) | Weights & Biases, Neptune AI | $0–$500/month for small teams |
| Data versioning | DVC (open source) | Pachyderm, LakeFS | $0–$1,000/month |
| Pipeline orchestration | Kubeflow, Airflow, Prefect (community) | Vertex AI Pipelines, SageMaker Pipelines | $0–$2,000/month |
| Model registry | MLflow Model Registry | SageMaker, Vertex AI, Azure ML | $0–$500/month |
| Feature store | Feast (open source) | Tecton, Vertex AI Feature Store | $0–$3,000/month |
| Model serving | KServe, BentoML, Seldon Core | SageMaker Endpoints, Vertex AI Prediction | $500–$10,000+/month (traffic dependent) |
| Drift monitoring | Evidently AI (open source) | WhyLabs, Arize AI, Fiddler AI | $0–$2,500/month |
| Unified MLOps platform | — | Databricks, SageMaker Studio, Vertex AI, Azure ML | $3,000–$20,000+/month at scale |
MLOps vs DevOps: Team Role Comparison
| Role | In DevOps | In MLOps | Unique MLOps Responsibilities |
|---|---|---|---|
| Developer / Data Scientist | Writes application code, unit tests, deploys via CI/CD | Builds and trains ML models, writes feature engineering code | Experiment tracking, model evaluation, training data curation |
| DevOps / ML Engineer | Manages CI/CD pipelines, infrastructure, and deployments | Builds and maintains ML training pipelines and model serving infrastructure | Training pipeline orchestration, model serving, drift monitoring setup |
| Data Engineer | Minimal overlap — data pipelines separate from DevOps | Core MLOps role — builds data pipelines, maintains feature stores, ensures data quality | Feature engineering, data versioning, data validation (Great Expectations) |
| SRE / Platform Engineer | Reliability, SLA management, shared platform tools | ML platform reliability, GPU/TPU cluster management, serving SLAs | Model serving reliability, inference latency SLOs, cost optimization |
| MLOps Engineer | No direct equivalent | Bridges data science and engineering — ML platform specialist | Full-stack: data versioning, training pipelines, model registry, drift monitoring |
MLOps vs DevOps: Decision Framework
Choosing the Right Model Lifecycle Approach
The MLOps vs DevOps decision is not an either/or — every MLOps team uses DevOps. The question is which additional ML-specific practices, tooling, and team roles you need to add on top of your DevOps foundation to reliably deploy and maintain machine learning models in production. The right answer depends on how many models you manage, how critical their accuracy is to business outcomes, how frequently data distributions shift, and whether you operate in a regulated industry with AI governance requirements.
Stick with DevOps for ML If:
- You are deploying 1–2 models with stable data distributions that require infrequent retraining — monthly or quarterly manual retraining is manageable without automation
- Your ML system uses static models that do not need to adapt to changing data — a model trained once and deployed as a fixed scoring function without ongoing maintenance
- You are in early exploration — your team has not yet validated that ML will provide production business value; full MLOps investment before product-market fit is premature
- Your models serve low-stakes decisions where accuracy degradation does not have significant business or safety consequences
- You lack dedicated ML engineering capacity — MLOps toolchain setup requires engineers with both ML and DevOps expertise that may not exist in your team yet
Invest in MLOps When:
- You manage 3 or more models in production — at this scale, manual tracking, deployment, and monitoring becomes untenable and centralized MLOps infrastructure pays off immediately
- Your models make high-stakes decisions — fraud detection, credit scoring, medical diagnosis, content moderation, or dynamic pricing where accuracy degradation has direct revenue or safety impact
- Your data distributions shift frequently — any environment where user behavior, market conditions, or sensor patterns change faster than your manual retraining cadence
- You operate in a regulated industry — financial services, healthcare, or government AI deployments requiring model explainability, bias testing, audit trails, and governance workflows
- You are deploying LLMs or generative AI — large model serving requires specialized infrastructure, prompt versioning, evaluation frameworks, and output quality monitoring that extend MLOps into LLMOps
MLOps vs DevOps: Quick Decision Table
| Question | If Yes → | If No → |
|---|---|---|
| Do you have 3+ models in production simultaneously? | MLOps platform investment justified | DevOps with basic experiment tracking adequate for now |
| Do your model accuracy metrics matter to business outcomes? | Drift monitoring and automated retraining essential | Manual monitoring and periodic retraining acceptable |
| Does your training data change frequently? | Continuous training pipeline required | Scheduled retraining pipeline sufficient |
| Are you in a regulated industry with AI governance needs? | Model registry, model cards, and bias testing required | Standard audit trail from DevOps pipeline adequate |
| Do multiple teams share features across models? | Feature store investment has clear ROI | Per-team feature engineering is manageable |
| Are you deploying LLMs or generative AI? | LLMOps practices and specialized serving needed | Standard MLOps serving platforms adequate |
Frequently Asked Questions
MLOps vs DevOps: Final Takeaways for 2026
The MLOps vs DevOps question resolves to a simple reality: DevOps is the foundation, and MLOps is the extension every team needs as soon as machine learning models graduate from experimentation to production accountability. DevOps solved the delivery problem for deterministic software — and that foundation remains essential. MLOps solves the delivery and sustainability problem for probabilistic, data-dependent systems that fail in ways DevOps pipelines were never designed to catch.
DevOps — Key Takeaways for ML Teams:
- Essential foundation — CI/CD, IaC, containers, and observability are prerequisites
- 78% global adoption — the most universal engineering practice in 2026
- Works well for deterministic software and simple, static ML deployments
- GitHub Actions and Jenkins can bootstrap basic ML pipelines at early maturity
- Cannot detect model drift, version training data, or trigger retraining
- Insufficient alone for multiple models, regulated industries, or high-stakes AI
MLOps — Key Takeaways:
- $3.4B market in 2026, growing to $25.93B by 2034 — 28.9% CAGR
- Addresses the 55% production failure rate of ML without governance
- Drift detection and automated retraining are the core differentiators
- Data versioning + experiment tracking + model registry = reproducibility
- EU AI Act compliance requires MLOps governance infrastructure in 2026
- Talent gap: 40% of orgs struggle to find engineers skilled in both ML and DevOps
Practical Recommendation for 2026:
Start your MLOps journey with two tools regardless of team size: MLflow for experiment tracking and DVC for data versioning. Both are open source, install in minutes, and immediately solve the reproducibility and experiment comparison problems that block most teams from reliable model deployment. From there, add a model registry (MLflow or your cloud provider’s), containerized model serving, and basic drift monitoring before investing in a full MLOps platform. The full MLOps vs DevOps transition is a maturity journey — match your tooling investment to the number of models you manage, the criticality of their accuracy, and the regulatory requirements you face. In the MLOps vs DevOps decision for 2026, the question is not which to choose — it is how far along the MLOps maturity curve your current model portfolio requires you to be.
Whether you are a data scientist ready to take your first model to production, a DevOps engineer adapting your pipelines for ML workloads, or an engineering leader building an AI delivery platform — the MLOps vs DevOps comparison gives you the complete framework to make the right infrastructure decisions. Explore the related comparisons below to complete your understanding of the modern AI delivery stack.
Related Topics Worth Exploring
Jenkins vs GitHub Actions
MLOps training pipelines need a CI/CD backbone. Compare Jenkins and GitHub Actions to understand which platform best supports ML pipeline orchestration — from experiment-triggering workflows to model evaluation gates and registry promotion automation.
DevSecOps vs DevOps
MLOps introduces unique security considerations — model poisoning, training data tampering, adversarial inputs, and AI supply chain risk. Understand how DevSecOps practices extend into the ML pipeline to protect models throughout their lifecycle from training to production.
AIOps vs Traditional IT Operations
AIOps applies machine learning to IT operations monitoring — making it both a consumer and a producer of MLOps practices. Explore how AIOps platforms handle model deployment, drift monitoring, and automated incident response in the context of IT operations intelligence.