Every minute of IT downtime costs enterprises an average of $300,000. Yet despite billions spent on monitoring tools, most IT teams still fight the same battle: too many alerts, too little time, and incidents discovered only after users are already impacted. The gap between how IT operations have always worked and what modern infrastructure demands has never been wider. AIOps — Artificial Intelligence for IT Operations — represents the most significant shift in how organizations manage their technology infrastructure since the move to cloud computing. With the AIOps market valued at $18.95 billion in 2026 and projected to reach $37.79 billion by 2031, this is no longer an emerging trend — it is the new operational standard for enterprises running complex, distributed systems. Whether you are a student exploring IT operations fundamentals, a developer building scalable systems, or an IT leader evaluating your operations strategy, understanding the difference between AIOps and Traditional IT Operations is essential for making informed decisions that align technology capabilities with business outcomes.
IT Operations Landscape in 2026
The complexity of modern IT environments has outpaced what human teams can manage manually. Organizations no longer operate monolithic applications in single data centers — they run hybrid and multi-cloud environments with microservices architectures, containerized applications, serverless functions, and distributed systems spanning global infrastructures. A single business transaction may touch dozens of services across multiple vendors and platforms simultaneously. Traditional IT monitoring approaches, built for simpler and more predictable systems, struggle to provide meaningful visibility in this complexity.
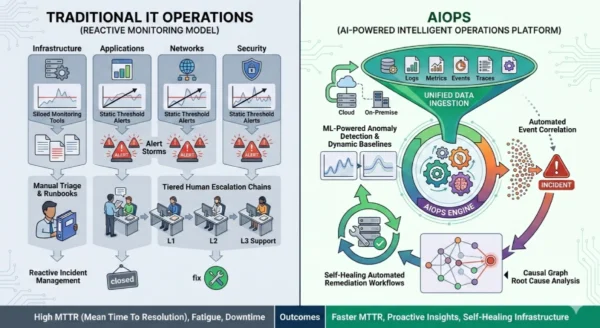
Traditional IT Operations: The Reactive Model
Definition
Traditional IT Operations, often called ITOps, refers to the established model of managing IT infrastructure through manual monitoring, rule-based alerting, and human-driven incident response. Built for predictable environments, it relies on teams of engineers watching dashboards, triaging alerts, and following documented runbooks to resolve issues after they occur. For decades it served organizations well — but the architecture it was designed for no longer reflects the reality of modern enterprise infrastructure. Static thresholds, siloed tooling, and reactive workflows form the core of the traditional model, making it increasingly inefficient as system complexity grows.
Advantages
- Proven and familiar: Decades of operational history, well-understood processes and established best practices
- Human judgment: Experienced engineers apply contextual reasoning and institutional knowledge that algorithms cannot replicate
- Lower upfront cost: No AI platform licensing, model training, or specialized skill investment required initially
- Simpler environments: Works reliably for stable, low-complexity infrastructure with predictable failure patterns
- Full control: Engineers understand every alert, threshold, and escalation path without black-box dependencies
- Regulatory clarity: Auditable manual processes are easier to document for compliance frameworks in regulated industries
Disadvantages
- Alert fatigue: 59% of IT leaders report too many alerts as their main source of inefficiency, burying critical signals in noise
- Reactive by design: Issues are detected only after users are already impacted, increasing downtime and business loss
- Data overload: Enterprise systems generate petabytes of logs and metrics annually — impossible to analyze manually at scale
- High MTTR: Manual investigation, context-gathering, and coordination across teams significantly extends resolution time
- Scaling ceiling: Each new service, cloud, or system adds proportional human workload with no efficiency gain
- Engineer burnout: Constant on-call pressure, repetitive triage, and overnight incidents degrade team performance and retention
Traditional IT Operations Core Components:
Monitoring Tools: Agent-based or agentless systems collecting metrics, logs, and events from individual infrastructure components. Alert Thresholds: Static rules triggering notifications when predefined limits are crossed, independent of context or history. Furthermore, Runbooks: Documented step-by-step procedures guiding engineers through known failure scenarios and standard resolutions. Additionally, Escalation Chains: Tiered human response structures routing incidents from Level 1 through Level 3 support based on severity and expertise. Moreover, Change Management: Manual approval workflows governing infrastructure modifications to minimize risk of unintended outages.
AIOps: The Intelligent Operations Platform
Definition
AIOps, a term coined by Gartner in 2016, stands for Artificial Intelligence for IT Operations. It describes platforms that combine big data analytics, machine learning, and automation to enhance and partially replace manual IT operations processes. Rather than waiting for metrics to cross static thresholds, AIOps continuously learns the normal operational baseline of every service, detects subtle deviations before they escalate, correlates related alerts across systems into single actionable incidents, performs automated root cause analysis, and triggers remediation — often without human intervention. AIOps does not simply speed up traditional IT operations; it fundamentally changes the operating model from reactive firefighting to proactive, predictive infrastructure management at machine speed and scale.
Advantages
- Proactive detection: ML-based anomaly detection identifies issues hours or days before they impact users or services
- Noise reduction: Intelligent alert correlation condenses thousands of alerts into prioritized, actionable incidents
- Faster MTTR: Automated root cause analysis reduces resolution time by up to 60% in hybrid environments
- Continuous learning: Models improve over time, becoming more accurate and context-aware with each incident handled
- Scalability: Manages exponentially growing telemetry volumes without proportional headcount increases
- Cross-domain visibility: Unified view across infrastructure, applications, networks, and cloud environments simultaneously
- Self-healing capability: Automated remediation resolves standard incidents without engineer involvement, freeing teams for strategic work
Disadvantages
- Implementation complexity: Requires clean, comprehensive data pipelines and mature CMDB before delivering full value
- Delayed ROI: Only a small subset of organizations achieve triple-digit ROI in year one; a quarter report negative returns from underused features
- Black-box risk: ML models can make opaque decisions that engineers struggle to audit, challenge, or explain to stakeholders
- Legacy integration challenges: Connecting diverse data sources and older systems remains the biggest adoption barrier
- Talent requirements: Effective AIOps demands data engineering, ML operations, and platform expertise beyond traditional ITOps skills
- SME friction: Many platforms assume 24/7 site reliability teams that small and medium enterprises do not staff
AIOps Core Capabilities:
Data Ingestion: Continuous aggregation of logs, metrics, events, traces, and configuration data from every system across the IT stack. Anomaly Detection: ML algorithms learning normal operational baselines and flagging deviations before they escalate to outages. Furthermore, Event Correlation: Intelligent grouping of related alerts from different systems into single actionable incidents, dramatically reducing noise. Additionally, Root Cause Analysis: Automated investigation identifying the precise source of issues by analyzing patterns, dependencies, and historical data. Moreover, Automated Remediation: Triggering predefined workflows — restarting services, scaling resources, creating tickets — without human intervention for standard failure scenarios.
Technical Architecture Deep Dive
Traditional IT Operations Architecture
- Siloed monitoring tools covering specific domains: network, application, infrastructure separately
- Static threshold-based alerting with predefined rules applied uniformly regardless of context
- Manual alert triage requiring engineers to investigate each notification individually
- Runbook-driven incident response following documented procedures for known failure types
- Tiered escalation chains routing unresolved issues through L1, L2, and L3 support levels
- Post-incident reviews as primary learning mechanism with no real-time pattern recognition
- Change advisory boards governing infrastructure modifications through manual approval workflows
AIOps Platform Architecture
- Unified data ingestion layer aggregating telemetry from all sources regardless of vendor or format
- ML-powered anomaly detection establishing dynamic baselines per service, time of day, and load pattern
- Correlation engine grouping related signals into single incidents with full cross-domain context
- Causal graph analysis pinpointing root cause by mapping dependencies across distributed systems
- Automated workflow execution triggering remediation scripts, scaling actions, and ticket creation
- Continuous model retraining improving detection accuracy from every incident handled
- Generative AI triage assistants summarizing incidents, suggesting next-best steps, and drafting communications
Incident Response Workflow Comparison
Traditional IT Incident Response
- Multiple monitoring tools generate separate alerts across network, app, and infrastructure
- On-call engineer receives alert notification, often during off-hours
- Engineer manually checks dashboards across multiple tools to gather context
- Team correlation meeting or Slack channel activated to share findings
- Root cause investigation through log analysis, configuration review, and trial and error
- Fix applied based on runbook or engineer experience, rollback if unsuccessful
- Post-incident review written as static document with limited future recall
AIOps Incident Response
- AIOps platform ingests telemetry from all systems simultaneously in real time
- ML anomaly detection flags deviation from baseline before user impact occurs
- Correlation engine groups 40+ related alerts into single prioritized incident
- Automated root cause analysis identifies precise source within seconds
- Self-healing workflow attempts automated remediation for standard failure patterns
- Engineer receives single enriched alert with full context, root cause, and recommended action
- Resolution data feeds model retraining, improving future detection and response accuracy
Monitoring Models Compared
| Monitoring Aspect | Traditional IT Operations | AIOps |
|---|---|---|
| Detection Method | Static thresholds triggering alerts when predefined limits are crossed | Dynamic ML baselines detecting anomalies relative to learned normal behavior |
| Alert Volume | High volume with significant noise, false positives, and duplicate notifications | Dramatically reduced through intelligent correlation and noise suppression |
| Root Cause Analysis | Manual investigation requiring engineer time, tool switching, and team coordination | Automated causal analysis surfacing root cause within seconds of detection |
| Response Speed | Reactive, hours after user impact depending on alert acknowledgment and escalation | Proactive, predicting and preventing issues before users experience impact |
| Scalability | Linear: each new service adds proportional monitoring and triage workload | Exponential: platform handles growing telemetry volumes without additional headcount |
Use Cases and Deployment Scenarios
When to Retain Traditional IT Operations
- Small, stable environments: Organizations running fewer than 50 services on predictable, well-understood infrastructure
- Air-gapped systems: Defense, government, and critical infrastructure where cloud-connected AIOps platforms face data sovereignty restrictions
- Budget-constrained teams: SMEs without resources for AIOps platform licensing, integration services, and skill development
- Legacy-heavy infrastructure: Organizations where the cost and complexity of connecting legacy systems to AIOps platforms exceeds near-term benefit
- Low change rate: Environments with infrequent deployments and stable architectures where incident frequency does not justify platform investment
When to Adopt AIOps
- High alert volume: Teams receiving thousands of alerts daily where manual triage is creating burnout and missed incidents
- Complex distributed systems: Microservices, Kubernetes clusters, and multi-cloud environments generating exponential telemetry
- MTTR pressure: Organizations where downtime costs exceed the investment in AI-powered incident prevention and faster resolution
- Scaling operations: IT teams that need to manage growing infrastructure without proportional headcount increases
- Regulated industries: Financial services, healthcare, and telecom where uptime, compliance, and audit trails demand intelligent monitoring
- DevOps integration: Teams embedding AIOps into CI/CD pipelines to detect issues earlier in the development lifecycle
Industry Adoption Patterns
| Industry | Traditional IT Operations Use Cases | AIOps Use Cases |
|---|---|---|
| Financial Services | Internal tooling, development environments, low-criticality back-office workloads | Real-time transaction monitoring, fraud detection, trading platform uptime, compliance reporting |
| Healthcare | Small clinic management systems, non-patient-facing administrative infrastructure | Hospital EHR availability, patient monitoring systems, HIPAA-compliant incident management |
| Telecommunications | Simple network segments with low change frequency and predictable traffic patterns | Network performance management, 5G infrastructure monitoring, customer experience assurance |
| E-commerce | Internal admin panels, staging environments, non-revenue-impacting workloads | Customer-facing store reliability, payment processing uptime, seasonal traffic autoscaling |
| Manufacturing | Factory floor OT networks, air-gapped systems, on-premises legacy infrastructure | IoT device monitoring, predictive maintenance, supply chain system availability |
12 Critical Differences: AIOps vs Traditional IT Operations
Aspect | Traditional IT Operations | AIOps |
|---|---|---|
| Operations Model | Reactive: issues detected and resolved after user impact occurs | Proactive: anomalies predicted and prevented before users experience impact |
| Alert Management | Static threshold rules generating high-volume, noisy, context-free notifications | ML-powered correlation condensing thousands of alerts into prioritized actionable incidents |
| Root Cause Analysis | Manual investigation requiring hours of engineer time across multiple tools | Automated causal analysis identifying root cause in seconds with full dependency mapping |
| MTTR Performance | Hours to days depending on incident complexity and team availability | Reduced by up to 60% through automated investigation and remediation workflows |
| Scalability | Linear scaling requiring proportional headcount increases as infrastructure grows | Handles exponential telemetry growth without additional operations staffing |
| Learning Capability | Static runbooks updated manually after post-incident reviews | Continuous model retraining incorporating every incident for improving future accuracy |
| Tooling | Multiple siloed monitoring tools covering individual infrastructure domains separately | Unified platform ingesting data from all sources with cross-domain correlation and context |
| Team Impact | High on-call burden, alert fatigue, and engineer burnout from constant reactive work | Reduced noise and automated triage freeing engineers for strategic and innovative work |
| Upfront Cost | Lower initial investment, leveraging existing monitoring tools and established processes | Higher platform licensing, integration services, and initial training investment required |
| Downtime Cost | Higher long-term cost from frequent incidents, slower resolution, and business impact | Significant reduction in downtime frequency and duration delivering measurable business ROI |
| Cloud Compatibility | Struggles with hybrid and multi-cloud visibility across diverse vendor environments | Designed for hybrid and multi-cloud architectures with native cloud provider integrations |
| Future Readiness | Increasingly inadequate for microservices, containers, and distributed architectures | Purpose-built for modern cloud-native environments with continuous capability expansion |
Implementation and Migration Strategy
Getting Started: Platform Selection
- Operations Audit: First, document current monitoring tooling, alert volumes, MTTR baselines, and on-call load to establish the benchmark AIOps must improve against.
- Data Readiness Assessment: Then, evaluate data quality, source coverage, and CMDB maturity — AIOps platforms require clean, comprehensive telemetry to deliver value.
- Business Case Development: Additionally, calculate the cost of current downtime, on-call staffing, and alert triage time to justify platform investment with concrete ROI projections.
- Vendor Evaluation: Furthermore, assess platforms like Dynatrace, ServiceNow, Splunk, IBM Watson AIOps, and Datadog against your specific environment complexity and integration requirements.
- Team Skill Assessment: Subsequently, identify gaps in data engineering, ML operations, and platform administration that require training or new hiring before deployment.
- Pilot Scope Definition: Finally, select a contained, high-impact use case — such as a single critical application — for initial deployment before expanding across the enterprise.
Migration Path: Traditional ITOps to AIOps
Phase 1: Foundation (Weeks 1-6)
- Audit all existing monitoring tools, data sources, and alert configurations
- Establish data pipelines connecting logs, metrics, events, and traces to central platform
- Clean and enrich CMDB with accurate service dependency mapping
- Define baseline MTTR, alert volume, and on-call metrics for ROI benchmarking
- Train core team on AIOps platform administration and ML operations fundamentals
Phase 2: Activation (Weeks 7-12)
- Deploy AIOps platform in observation mode alongside existing tools without replacing them
- Allow ML models to learn operational baselines before enabling automated alerting
- Validate anomaly detection accuracy and tune models to reduce false positives
- Implement alert correlation rules and begin consolidating duplicate notifications
- Build initial automated remediation playbooks for standard, low-risk failure scenarios
Phase 3: Optimization (Weeks 13-20)
- Expand automated remediation to cover broader failure scenarios with proven playbooks
- Decommission redundant legacy monitoring tools as AIOps coverage matures
- Integrate AIOps platform with ITSM, CI/CD pipelines, and change management workflows
- Measure MTTR improvement, alert volume reduction, and on-call load against baseline
- Present ROI evidence to leadership and plan enterprise-wide expansion roadmap
Implementation Best Practices
Success Factors
- Start with data foundation — AIOps without clean, comprehensive telemetry delivers poor results
- Run AIOps alongside traditional tools in parallel before replacing existing monitoring
- Define clear success metrics before launch so ROI measurement is objective and credible
- Start automation conservatively with low-risk playbooks, expand scope as confidence builds
- Involve on-call engineers in tuning — their operational knowledge improves model accuracy significantly
- Treat AIOps as an operating model change, not a tool deployment, to avoid shallow adoption
Common Pitfalls
- Never deploy AIOps without first solving data quality and CMDB accuracy issues
- Avoid enabling aggressive automation before models have learned accurate baselines
- Do not attempt to migrate all tools simultaneously — incremental transition reduces risk substantially
- Resist purchasing platforms with features far beyond current operational maturity
- Never ignore the human change management challenge — engineer trust in automation must be earned gradually
- Do not measure ROI too early — ML models need months of data before delivering optimal performance
Cost, ROI and Learning Curve Analysis
Implementation Timeline
Traditional ITOps: Days to configure existing tools
AIOps: 3-6 months to full production value
Skill Investment
Traditional ITOps: Established skills, minimal new learning
AIOps: 2-4 months to platform proficiency
MTTR Impact
Traditional ITOps: Baseline — hours to days
AIOps: Up to 60% reduction at scale
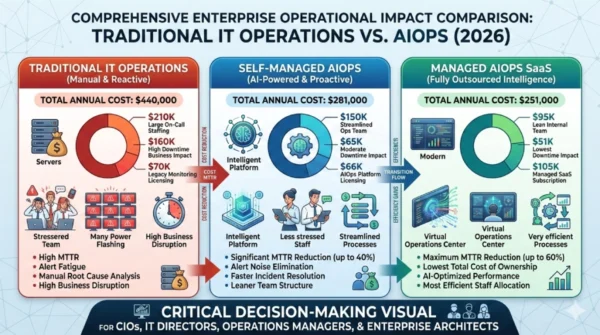
Total Cost of Ownership: Enterprise IT Operations First Year
| Cost Component | Traditional IT Operations | AIOps (Self-Managed) | AIOps (Managed/SaaS) |
|---|---|---|---|
| Platform Licensing | $15,000 (existing monitoring tools) | $40,000 | $60,000 (includes support) |
| Training & Skill Development | $5,000 | $25,000 | $15,000 |
| Operational Staffing | $180,000 (large on-call team) | $120,000 (smaller optimized team) | $80,000 (lean team with vendor support) |
| Downtime Business Cost | $240,000 (estimated annual impact) | $96,000 (60% MTTR reduction) | $96,000 (60% MTTR reduction) |
| Total First Year | $440,000 | $281,000 | $251,000 |
| Net Position vs Traditional | Baseline | -36% total cost | -43% total cost |
Unlike the Kubernetes vs Docker Swarm comparison where Kubernetes costs significantly more upfront, AIOps often delivers net cost reduction even in year one when downtime costs are properly factored into the calculation. The critical variable is infrastructure complexity — organizations with high incident frequency and significant downtime impact realize positive ROI faster. Organizations with stable, low-complexity environments may find traditional ITOps remains more cost-effective. Managed AIOps services dramatically reduce the implementation risk and skill requirements, making the transition viable for mid-sized teams without dedicated ML operations expertise.
Strategic Decision Framework
Matching Operations Model to Organizational Maturity
The choice between AIOps and Traditional IT Operations is not simply a technology decision — it is a strategic commitment to a different operational philosophy. Similar to how the Kubernetes vs Docker Swarm decision requires honest assessment of team readiness and workload complexity, AIOps adoption demands clear-eyed evaluation of data maturity, infrastructure complexity, and business impact of downtime. Organizations achieve the best outcomes by choosing the model that amplifies current team capability rather than introducing complexity that outpaces organizational readiness.
Decision Matrix
| Decision Factor | Retain Traditional IT Operations When… | Adopt AIOps When… |
|---|---|---|
| Infrastructure Complexity | Fewer than 50 services on predictable, stable architecture | 50+ services across hybrid, multi-cloud, or microservices environments |
| Alert Volume | Manageable daily alert count without significant noise or fatigue | Thousands of daily alerts creating triage overload and missed critical incidents |
| Downtime Cost | Business impact of outages is limited and acceptable with current MTTR | Each hour of downtime costs $100,000+ making MTTR reduction a business priority |
| Team Size | Small IT teams where AIOps platform complexity exceeds available management capacity | Medium to large teams with dedicated SRE or platform engineering resources |
| Data Maturity | Fragmented data pipelines and poor CMDB accuracy that would undermine AIOps models | Clean, comprehensive telemetry across all systems with well-maintained service mapping |
| Budget | Limited IT budget where platform licensing and integration costs are prohibitive | Business case for AIOps supported by measurable downtime cost reduction potential |
| Regulatory Environment | Air-gapped or highly restricted environments incompatible with cloud-connected platforms | Industries requiring detailed audit trails and compliance reporting that AIOps automates |
| Growth Trajectory | Stable infrastructure with no planned major expansion or architecture changes | Rapid growth expected requiring scalable operations without proportional headcount growth |
Progressive AIOps Adoption Approaches
Incremental Adoption: Start with Noise Reduction
Many organizations begin AIOps adoption with a single, focused goal before expanding:
- Deploy AIOps solely for alert correlation on the highest-alert-volume system first
- Measure noise reduction and on-call hours saved to establish concrete ROI proof
- Expand to anomaly detection once correlation models demonstrate accuracy
- Add automated remediation only after team trust in model decisions is established
- Scale platform coverage across additional services as value is validated
Full Platform Strategy: Enterprise-Wide Deployment
Organizations with mature data foundations and clear business cases can pursue broader deployment:
- Select enterprise AIOps platform covering infrastructure, application, and security telemetry
- Deploy across all critical services simultaneously with parallel traditional monitoring
- Integrate with ITSM, change management, and CI/CD pipelines from day one
- Build center of excellence for AIOps operations, model governance, and continuous improvement
- Measure enterprise ROI quarterly and expand automation scope based on proven playbook performance
Frequently Asked Questions: AIOps vs Traditional IT Operations
Making Strategic IT Operations Decisions in 2026
The choice between AIOps vs Traditional IT Operations represents a fundamental decision about organizational readiness for the complexity that modern infrastructure demands. Both models can deliver reliable IT operations when applied appropriately — the right choice depends on honest assessment of infrastructure complexity, data maturity, business impact of downtime, and team capability rather than following market trends.
Retain Traditional IT Operations When:
- Infrastructure is stable, predictable, and below 50 services in complexity
- Alert volumes are manageable without significant noise or burnout
- Data pipelines and CMDB are too fragmented to support AIOps accuracy
- Budget constraints make platform licensing and integration costs prohibitive
- Air-gapped or highly regulated environments restrict cloud-connected platforms
- Business impact of current downtime does not justify platform investment
Adopt AIOps When:
- Alert fatigue is degrading engineer performance and causing missed critical incidents
- Hybrid or multi-cloud architecture has made manual visibility impossible
- MTTR improvement has clear, measurable business value justifying investment
- Infrastructure is growing faster than headcount can scale to manage it
- Downtime costs in regulated industries demand proactive detection and faster resolution
- Team is ready for operational model transformation, not just new tooling
Strategic Recommendation for 2026:
Evaluate AIOps adoption based on operational pain, not market pressure. Organizations suffering genuine alert fatigue, escalating on-call burden, and MTTR that is measurably harming business outcomes have a clear, data-backed case for AIOps investment. Organizations running stable, simple environments gain nothing from AIOps complexity beyond increased platform cost and integration overhead. The most successful AIOps deployments begin with a focused use case — noise reduction or a single critical application — demonstrating measurable ROI before expanding platform scope. Just as the decision between Kubernetes and Docker Swarm should align platform capability with team maturity, the decision to adopt AIOps should match organizational readiness with infrastructure complexity rather than adopting AI for its own sake.
Whether you are a student learning IT operations fundamentals, a developer building observability into distributed systems, or an IT leader evaluating your operations strategy, understanding that AIOps and Traditional IT Operations represent different points on the complexity-versus-automation spectrum enables decisions that genuinely improve team productivity, system reliability, and business outcomes. The competitive advantage comes not from adopting the most advanced platform, but from choosing and executing the model that best fits current capabilities while building toward the future your infrastructure complexity demands.
Related Topics Worth Exploring
Kubernetes vs Docker Swarm
Understand the container orchestration platforms that AIOps monitors — comparing architecture, cost, and use cases for the environments generating your operational telemetry.
Observability vs Monitoring
Explore the difference between traditional monitoring and modern observability — the data foundation that determines how effectively AIOps platforms can operate.
DevSecOps vs Traditional DevOps
Discover how security integration transforms software delivery pipelines and connects with AIOps for unified security and operations intelligence across the enterprise.