Introduction
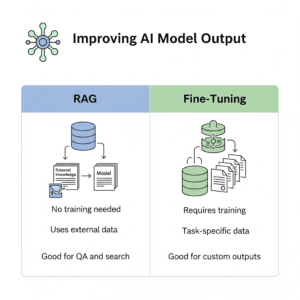
Retrieval Augmented Generation vs Fine-Tuning is a key choice when it comes to improving language model performance—and the two take very different approaches. RAG brings in relevant facts from external sources before generating a response, which makes it great for delivering up-to-date or domain-specific answers. Fine-Tuning, by contrast, retrains the model on a new dataset to make it more precise for a specific task. The right choice depends on whether you need flexibility with current information or laser focus on a narrow use case.
Retrieval Augmented Generation
Retrieval augmented generation is a method that combines both retrieval and generation processes in natural language processing. In this approach, instead of generating text entirely from scratch, the model retrieves relevant information from a pre-existing database or corpus and then generates text based on that retrieved information.
Example: A chatbot that uses retrieval augmented generation might look up answers from a knowledge base and then generate responses based on that retrieved information.
Advantages:
- Can produce more coherent and contextually relevant responses compared to traditional text generation models.
- Can reduce the risk of generating incorrect or misleading information as it relies on existing data.
Disadvantages:
- Dependent on the quality and relevance of the retrieved information.
- May not be suitable for generating highly creative or novel content.
Technical Characteristics:
- Combines information retrieval techniques with text generation models.
- Utilizes large databases or corpora to retrieve relevant information.
Common Use Cases and Real-World Applications:
- Customer support chatbots that fetch answers from knowledge bases.
- Automated content creation tools that use existing articles for inspiration.
Fine-Tuning
Fine-tuning is a process in machine learning where a pre-trained model is further trained on a specific dataset or task to improve its performance on that particular task. Instead of training a model from scratch, fine-tuning starts with a pre-trained model and adjusts its parameters to adapt to the new task.
Example: Fine-tuning a language model like GPT-3 on a medical dataset to generate more accurate medical text.
Advantages:
- Requires less data and computational resources compared to training a model from scratch.
- Can achieve better performance on specific tasks due to leveraging pre-trained knowledge.
Disadvantages:
- May suffer from catastrophic forgetting, where fine-tuning on a new task erases previously learned knowledge.
- Dependent on the quality of the pre-trained model for achieving desired results.
Technical Characteristics:
- Adjusts the parameters of a pre-trained model for a specific task.
- Involves updating weights through backpropagation using task-specific data.
Common Use Cases and Real-World Applications:
- Text classification tasks like sentiment analysis or spam detection.
- Image recognition tasks for specific domains like medical imaging or satellite imagery.
Understanding the Key Differences in Retrieval Augmented Generation vs Fine-Tuning
Retrieval Augmented Generation | Fine-Tuning |
|---|---|
| Generates responses by retrieving and adapting relevant information from a large pool of data | Modifies a pre-trained model on a specific task or dataset |
| Relies on retrieving external knowledge during the generation process | Focuses on refining the existing model’s parameters |
| Suitable for tasks where additional context or information retrieval is crucial | Ideal for improving performance on a specific task with fine adjustments |
| May require a larger computational overhead due to information retrieval | Typically quicker to implement as it involves tweaking an existing model |
| Can potentially handle more diverse and complex tasks with access to external knowledge | Primarily enhances performance on the specific task it is fine-tuned for |
| Less prone to overfitting as it can incorporate broader context | May be more susceptible to overfitting if fine-tuned excessively |
| Supports a more generalized approach to various tasks by leveraging external data | Optimizes the model for a specific task, potentially sacrificing generalization |
| Can generate more creative and contextually appropriate responses with external knowledge | Tends to produce more task-specific and optimized outputs |
| Often used in scenarios where a system needs to adapt to dynamic or evolving information | Applied when a model needs to excel in a particular domain or task |
| Requires robust mechanisms for information retrieval and adaptation during generation | Relies on a thorough understanding of the task to fine-tune the model effectively |
| Encourages exploration of broader knowledge sources to enhance response quality | Focuses on optimizing model parameters for a narrow task domain |
| Can potentially improve response quality by incorporating real-time or up-to-date external information | Enhances performance by tailoring the model to specific task requirements |
| Enhances adaptability and flexibility by leveraging external knowledge resources | Improves task-specific performance by adjusting existing model weights |
| More resource-intensive during the generation process due to information retrieval operations | Less resource-demanding for fine-tuning compared to retrieval-based approaches |
| Can be more beneficial in scenarios where a system needs to understand and respond based on a wide range of topics | Effective when the focus is on optimizing performance for a specific task or domain |
Practical Implementation
Exploring the Power of Retrieval Augmented Generation Versus Fine-Tuning refers to comparing two approaches in natural language processing tasks. Retrieval-augmented generation involves retrieving relevant information before generating text, while fine-tuning focuses on fine-tuning a pre-trained model for specific tasks.
Working Code Snippets
Example code for retrieval-augmented generation
from transformers import RagTokenizer, RagRetriever, RagSequenceForGeneration
tokenizer = RagTokenizer.from_pretrained("facebook/rag-token-nq")
retriever = RagRetriever.from_pretrained("facebook/rag-token-nq", index_name="exact")
model = RagSequenceForGeneration.from_pretrained("facebook/rag-token-nq", retriever=retriever)
input_text = "What is quantum computing?"
inputs = tokenizer(input_text, return_tensors="pt")
generated = model.generate(**inputs)
print(tokenizer.batch_decode(generated, skip_special_tokens=True))
Example code for fine-tuning
from transformers import Trainer, TrainingArguments, GPT2Tokenizer, GPT2LMHeadModel
from datasets import load_dataset
model = GPT2LMHeadModel.from_pretrained("gpt2")
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
dataset = load_dataset("wikitext", "wikitext-2-raw-v1")
# Tokenization
def tokenize(example):
return tokenizer(example["text"], truncation=True, padding="max_length", max_length=128)
dataset = dataset.map(tokenize, batched=True)
# Training setup
training_args = TrainingArguments(output_dir="./results", per_device_train_batch_size=2, num_train_epochs=1)
trainer = Trainer(model=model, args=training_args, train_dataset=dataset["train"])
trainer.train()
Step-by-Step Implementation Guide
- Identify the NLP task you want to work on.
- For retrieval-augmented generation:
- Implement a function to retrieve relevant information.
- Develop a text generation function that uses the retrieved information.
- Combine the functions to form the retrieval-augmented generation process.
- For fine-tuning:
- Prepare your data for fine-tuning.
- Use a pre-trained model and fine-tune it on your specific data.
Best Practices and Optimization Tips
- For retrieval-augmented generation, ensure efficient retrieval mechanisms to avoid delays.
- Fine-tuning: Utilize transfer learning by starting with a pre-trained model to speed up training.
- Experiment with different retrieval and fine-tuning strategies to find the best approach for your specific task.
Common Pitfalls and How to Fix Them
- Pitfall: Poor retrieval quality can impact the generated text’s relevance.
- Fix: Improve retrieval algorithms or expand the retrieval sources for better results.
- Pitfall: Overfitting during fine-tuning can lead to poor generalization.
- Fix: Regularize the training process, use dropout, or adjust the learning rate to prevent overfitting.
Frequently Asked Questions
What is “Retrieval-Augmented Generation”? How is it different from fine-tuning?
Retrieval-augmented generation combines pre-existing information with AI-generated content, allowing for more diverse and contextually relevant responses. Fine-tuning, on the other hand, involves tweaking a pre-trained model for specific tasks.
Why is Retrieval-Augmented Generation considered more versatile?
Retrieval-augmented generation can access a broader range of information beyond the model’s training data, making it more adaptable to various scenarios and potentially generating more creative outputs.
Can you provide an example of when one would choose Retrieval-Augmented Generation over fine-tuning?
Sure! If you need a chatbot to provide personalized responses based on vast amounts of external data like news articles or customer reviews, retrieval-augmented generation would be a better choice for generating contextually rich and diverse answers.
How does Retrieval-Augmented Generation affect the training process compared to fine-tuning?
Retrieval-augmented generation may require additional training to effectively incorporate retrieval mechanisms and balance between the pre-existing and generated content. Fine-tuning typically involves adjusting fewer parameters for a specific task.
Are there any limitations to using Retrieval-Augmented Generation over fine-tuning?
While retrieval-augmented generation can offer more diverse outputs, it may introduce complexity in managing the retrieval mechanisms and ensuring the generated content remains coherent and relevant to the input. Fine-tuning, on the other hand, may be more straightforward for specific tasks.
Conclusion
Retrieval Augmented Generation and Fine-Tuning are two powerful techniques with distinct differences. The comparison of Retrieval Augmented Generation vs Fine-Tuning highlights the trade-off between generating diverse, context-rich responses and customizing models for specific tasks. While Retrieval Augmented Generation excels in producing varied and relevant outputs, Fine-Tuning is best suited for adapting a pre-trained model to a particular domain. Choosing between the two depends on whether you need flexibility and context or precision for task-specific applications.