Distributed computing spreads work across many separate
computers that talk over a network, each with its own memory.
Parallel computing splits one job across many processors
inside a single machine, usually sharing the same memory. So distributed
computing aims at scale and reliability, while parallel computing aims at
raw speed. In short, the split comes down to memory and goal: separate
machines passing messages, or shared memory racing through one task.
Distributed and parallel computing both run many operations at once, so
students often treat them as the same thing. Yet they differ in where the work
runs, how the parts talk, and what problem they solve.
Because both appear across operating-systems and computer-architecture
courses, the distinction matters for exams and interviews. This guide defines
each model, compares them in detail, and shows when to use which.
They sit close to high-performance computing, so it also helps to know
grid vs cluster computing
What is Distributed Computing?
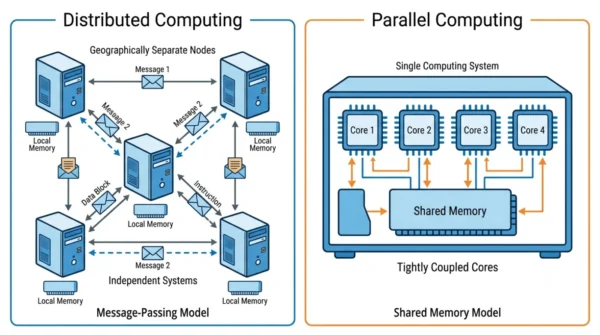
Distributed computing connects many independent computers,
called nodes, over a network so they cooperate on a task. Crucially, each node
has its own private memory and its own clock, so the nodes
coordinate by passing messages rather than sharing memory.
Because the nodes are only loosely coupled, the system scales out easily and
survives failures. For example, protocols such as HTTP and gRPC carry the
messages, and one node can drop out while the others carry on. As a result,
distributed computing suits large, always-on services.
Advantages of distributed computing:
- Scales horizontally, so you add capacity by adding machines.
- Fault tolerant, because a failed node can be rerouted around.
- Can span locations, which suits global services.
Disadvantages of distributed computing:
- Network latency and failures make it harder to program.
- Keeping data consistent across nodes is tricky.
- Coordination overhead grows as nodes are added.
What is Parallel Computing?
Parallel computing splits a single problem into smaller parts
and runs them at the same time on multiple processors or cores inside
one machine. Usually those processors share the same memory,
so they exchange data quickly through that shared space instead of over a
network.
Because the parts are tightly coupled and the memory is shared, parallel
computing reaches very low latency and high speed. So it shines on
compute-heavy jobs, such as scientific simulations and training
machine-learning models. Hardware models like SIMD and MIMD describe how the
processors divide the work.
Advantages of parallel computing:
- Very fast, since shared memory avoids network delays.
- Simpler model, especially with a shared address space.
- Great for dividing one heavy computation into parts.
Disadvantages of parallel computing:
- Limited by one machine, so it scales up rather than out.
- A hardware failure can stop the whole job.
- Shared memory can cause contention between processors.
Distributed vs Parallel Computing: Comparison Table
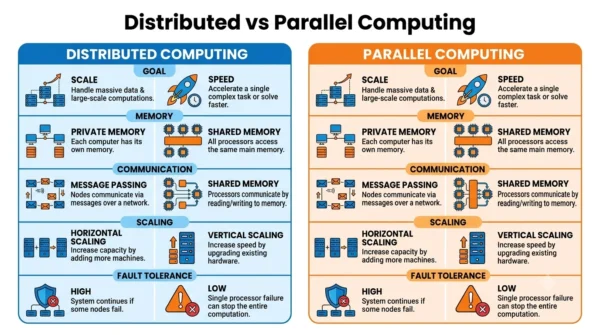
| Aspect | Distributed Computing | Parallel Computing |
|---|---|---|
| Definition | Many networked computers cooperate on tasks | Many processors in one machine work on one task |
| Main goal | Scale, sharing, and reliability | Faster computation (speed-up) |
| Hardware | Multiple independent computers (nodes) | Multiple processors or cores in one system |
| Memory | Each node has private memory | Usually shared memory (one address space) |
| Communication | Message passing over a network | Shared memory or a fast interconnect |
| Coupling | Loosely coupled | Tightly coupled |
| Clock | No common clock; nodes are independent | Often a common clock |
| Latency | Higher (network delays) | Lower (within one machine) |
| Scaling | Horizontal (add more machines) | Vertical (add more processors or cores) |
| Fault tolerance | High; a failed node reroutes | Low; one failure can stop the job |
| Location | Can be geographically spread out | Single location, one system |
| Programming model | More complex (remote data, failures) | Simpler, especially shared-memory |
| Examples | Hadoop, Cassandra, CDNs, Kubernetes | GPUs, multicore CPUs, MPI, OpenMP |
Memory and How They Work
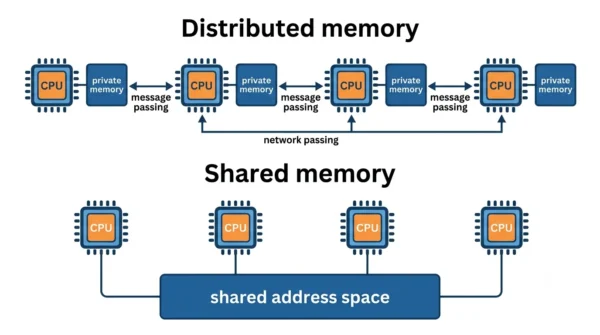
The clearest way to tell the two apart is the memory model.
In distributed computing, every node holds its own data, so the only way to
share is to send a message across the network. Therefore the design must
handle delays, lost messages, and nodes that disagree.
In parallel computing, the processors usually read and write a
shared memory, so they swap data almost instantly. However,
that shared access needs care, because two processors writing the same
location at once can clash. Models such as SIMD run one instruction over many
data items, while MIMD runs different instructions at once.
The line can blur, of course. A cluster running MPI does “distributed-memory
parallel” computing, since it splits one job across networked nodes. Even so,
the rule of thumb holds: distributed means separate memories and messages,
while parallel means shared memory and speed.
Applications of Distributed and Parallel Computing
Each model lands where its strengths fit, so both appear across modern
computing.
- Distributed in big data: frameworks such as Apache Hadoop
and databases like Cassandra spread storage and processing across many
machines. - Distributed on the web: content delivery networks and cloud
services use distributed nodes to stay fast and available worldwide. - Parallel in science: weather models, physics simulations,
and other heavy maths rely on parallel processing for speed. - Parallel in AI and graphics: GPUs train machine-learning
models and render graphics by running thousands of operations at once.
So distributed computing powers large, spread-out services, while parallel
computing accelerates single heavy computations.
When to Use Distributed or Parallel Computing
Choose distributed computing when the work must scale across
machines, stay available, or serve users in many places. For instance, a
global web app or a big-data pipeline fits this model well.
Choose parallel computing when one heavy computation must
finish faster on a single, powerful machine. Scientific simulations and model
training are classic cases, because they split cleanly into parts.
In practice, large systems combine both. A distributed cluster may hold many
machines, while each machine runs parallel processing inside, so the design
gets both scale and speed.
Interview Questions
separate computers, each with private memory, that coordinate by passing
messages over a network, mainly for scale and reliability. Parallel
computing uses many processors inside one machine that usually share
memory, mainly for speed. So distributed means separate memories, while
parallel means shared memory.
a cluster running MPI does distributed-memory parallel computing.
However, classic parallel computing assumes one machine with shared
memory, whereas distributed computing assumes separate machines with
private memory. So the memory model is what sets them apart.
when one node fails, so the service keeps running. A parallel system, by
contrast, lives inside one machine, so a hardware failure there can stop
the whole job. That independence is also why distributed systems scale
out so well.
or Single Instruction Multiple Data, runs the same instruction across
many data items at once, which suits GPUs. MIMD, or Multiple Instruction
Multiple Data, lets processors run different instructions on different
data, which suits multicore CPUs.
Frequently Asked Questions
each with its own memory, that coordinate by passing messages, mainly
for scale and reliability. Parallel computing splits one task across
many processors in a single machine that usually share memory, mainly
for speed. So the key difference is separate memories and messages
versus shared memory and speed.
handle more work. Because each node is independent, the system can grow
almost without limit, and it spreads load across the nodes. As a result,
it handles growing workloads better than a single machine can.
multicore processors in phones and laptops run tasks in parallel, and
the GPUs in computers render graphics and train AI models by doing many
operations at once. So even ordinary hardware relies on parallel
processing for speed.
can fall out of sync across nodes. Because there is no shared clock or
shared memory, they also need careful coordination and consistency
rules. So robust communication protocols and failure handling are
essential.
Distributed computing wins when you need scale, availability, or a
global reach, whereas parallel computing wins when one heavy job must
finish faster. In fact, many large systems use both together, with
parallel processing inside a distributed cluster.
Wrapping Up
Distributed and parallel computing both do many things at once, yet they
differ at the core. Distributed computing uses separate machines with private
memory that pass messages, while parallel computing uses shared memory inside
one machine for speed.
Remember the simple rule: distributed computing scales out for reliability,
while parallel computing scales up for speed. Because real systems often need
both, they are frequently combined, with parallel processing running inside a
distributed cluster.
Related reading on DiffStudy: