Logical data independence is the ability to change the conceptual (logical) schema, such as adding an attribute or splitting a table, without changing the external views or the application programs. Physical data independence is the ability to change the internal (physical) schema, such as switching storage or adding an index, without changing the conceptual schema. In short, logical independence protects applications from structural change, while physical independence protects the structure from storage change. Logical independence is harder to achieve, so physical independence is far more common.
These two ideas, logical and physical data independence, are core to any database management system. Both sit at the heart of the DBMS and GATE syllabus. Students often blur which schema each one changes and which higher level it protects.
The whole idea rests on the three-schema architecture, so we start there. Then this guide defines each type of data independence, compares them in a detailed table, and shows where each one matters with a concrete example. By the way, do not confuse this DBMS topic with the operating-system idea of logical vs physical memory addresses, which is a different subject entirely.
If you are still building the basics, the wider CS fundamentals hub ties these database concepts together with the rest of computer science.
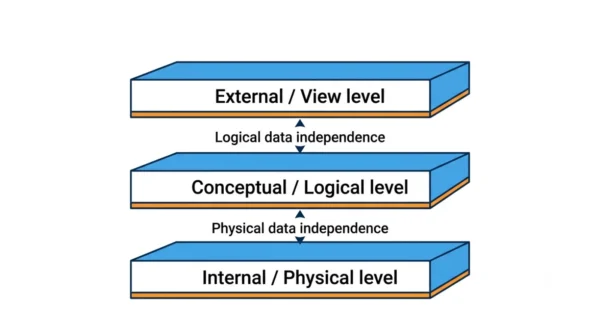
The Three-Schema Architecture
Before comparing the two, you need the ANSI-SPARC three-schema model. A DBMS describes the same data at three levels, so each user group sees only what it needs.
- External (view) level: what each user or application sees. There can be many views, and each hides the rest of the database.
- Conceptual (logical) level: the whole logical structure, that is, the tables, attributes, and relationships, without storage details.
- Internal (physical) level: how the data is actually stored, such as files, indexes, and compression on disk.
Data independence is the capacity to change the schema at one level without changing the schema at the next higher level. So the two flavours simply name which boundary you protect. Logical independence guards the external level, while physical independence guards the conceptual level. As a result, the mappings between levels absorb the change instead.
What is Logical Data Independence?
Logical data independence is the ability to modify the conceptual (logical) schema without affecting the external schemas or the application programs that read the data. In other words, you can reshape the logical structure, and existing views and apps keep working.
For example, you might add a new attribute, remove an unused one, split one table into two, or merge two records together. Because logical independence holds, the mapping between the conceptual and external levels absorbs that change. So the application keeps seeing its old view, even though the underlying structure moved.
This one is harder to achieve, though. Applications depend heavily on the logical structure, so a logical change is more likely to ripple up into the views. It also insulates the application program from operations such as splitting or combining records, which is exactly why it is valuable yet tricky.
Advantages of logical data independence:
- Seamless adaptability, since you can modify the logical structure without rewriting applications.
- Future-proofing, because the data systems can evolve as business needs change.
- Stronger security, as you can add restricted views without disturbing the core schema.
- Less rework, so developers avoid touching every app for one structural change.
Disadvantages of logical data independence:
- Hard to achieve fully, because applications lean so heavily on the logical structure.
- Complex mappings, since the conceptual-to-external mapping must track every change.
- Legacy friction, as old systems can be difficult to fit to new logical frameworks.
What is Physical Data Independence?
Physical data independence is the ability to change the internal (physical) schema without altering the conceptual schema or the application programs. So you can tune how data is stored, and the logical structure above it stays untouched.
For example, you might move data to a faster device, change the file organisation, add or drop an index, or switch the compression. Because physical independence holds, the mapping between the conceptual and internal levels absorbs that change. As a result, applications run optimization changes without noticing the storage moved.
This one is easier to achieve, and it is far more common in practice. The conceptual schema does not care which device holds the bytes, so storage tuning rarely leaks upward. Such changes are performed mainly to improve performance, which is why DBAs use this independence every day.
Advantages of physical data independence:
- Performance optimization, so you can adjust storage details for faster queries.
- Data integrity assurance, because the logical structure stays consistent through physical changes.
- Easier maintenance, since storage upgrades happen without touching schemas or apps.
- Lower risk, as a storage swap rarely ripples up into the conceptual level.
Disadvantages of physical data independence:
- Limited reach, since it does not insulate apps from logical or structural changes.
- Tuning effort, because choosing the right indexes and layout still takes skill.
- Over-optimization risk, as aggressive storage tweaks can hurt some access patterns.
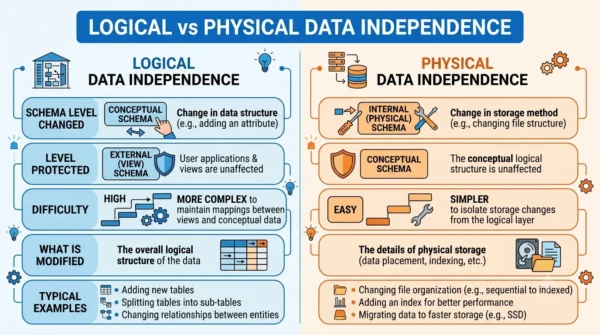
Logical vs Physical Data Independence: Comparison Table
| Aspect | Logical Data Independence | Physical Data Independence |
|---|---|---|
| Schema changed | Conceptual (logical) schema | Internal (physical) schema |
| Level protected | External schema and applications stay unaffected | Conceptual schema stays unaffected |
| Change absorbed by | Mapping between conceptual and external schema | Mapping between conceptual and internal schema |
| When you use it | When the structure of the database is altered | When changes are made to improve performance |
| Typical changes | Add or remove an attribute, split or merge tables | Change storage device, file organisation, or indexes |
| Insulation from record changes | Insulates apps from splitting or combining records | Does not insulate apps from such logical changes |
| Difficulty | Difficult, since relationships and data must stay intact | Easier, since it mainly moves data between devices |
| How common | Rarer and harder to fully achieve | More common and routinely achieved |
| Best-fit environment | Application-centric, dynamic business requirements | Performance-centric, database efficiency tuning |
| Prioritise when | Applications heavily influence data structures | Storage and speed need fine-tuning |
| Main focus | Adapt to changing data needs without disrupting operations | Fine-tune storage details for better efficiency |
| Security role | Enhances adaptability and the use of security measures | Allows optimization without compromising logical structures |
| Goal | Flexibility of the data model | Performance of the storage layer |
| Who relies on it | Application developers and data architects | Database administrators tuning storage |
| Example | Adding a column without rewriting reports | Moving a table from disk to SSD |
A Worked Example
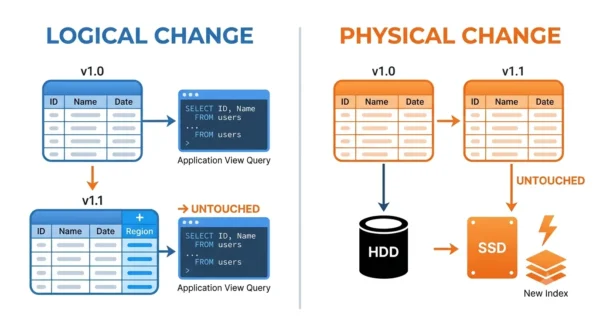
One small scenario makes the difference clear. Picture an Employee table that many reports and apps already read.
Logical change. Suppose the business now needs an email column on that table. You add the attribute to the conceptual schema. Thanks to logical data independence, the old reports that select only name and salary still run unchanged. The conceptual-to-external mapping quietly hides the new column from views that do not ask for it.
Physical change. Now suppose queries feel slow. So the DBA moves the table from a hard disk to an SSD and adds an index on the email column. Thanks to physical data independence, the conceptual schema does not change at all, and every application keeps working. Only the internal-to-conceptual mapping shifts to point at the new storage.
Notice the pattern. A logical change risks the applications, while a physical change stays safely below the conceptual level. That is exactly why logical independence is the harder of the two to guarantee.
When Each One Matters
You rarely choose one and abandon the other, because a good DBMS provides both at once. Still, the priorities differ by situation.
Lean on logical independence in application-centric environments. When applications heavily influence the data structures, this independence keeps crucial operations running through change. It also suits dynamic business requirements, since it gives the agility to evolve the model quickly.
Lean on physical independence in performance-centric environments. When optimising the database is the goal, this independence lets you fine-tune storage without touching logical structures. So it helps any team that wants maximum efficiency while preserving data integrity.
In short, the two are not a real either-or choice. Most systems use both together, and architects simply weigh which boundary needs more protection right now.
Interview Questions
Frequently Asked Questions
Wrapping Up
Logical and physical data independence solve the same problem at two different boundaries of the three-schema architecture. Logical independence lets the conceptual schema change without breaking views, while physical independence lets the internal schema change without breaking the conceptual model.
Remember the simple rule. Logical independence sits between the external and conceptual levels and is harder to achieve, whereas physical independence sits between the conceptual and internal levels and is easier and more common. They are not a real battle, since a strong DBMS delivers both. Knowing that distinction is enough to answer most exam and interview questions on the topic.
Related reading on DiffStudy: