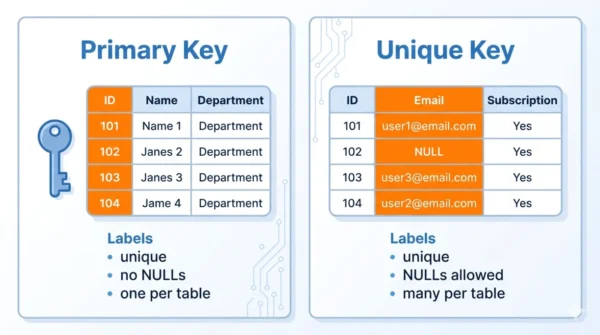
A primary key uniquely identifies every row, allows no NULLs, and a table has exactly one. A unique key also enforces uniqueness on a column, but it allows NULLs, and a table can have many. So the primary key is the main row identifier, while a unique key is an extra uniqueness rule. In short, every primary key is unique, yet not every unique key is the primary key.
Primary keys and unique keys are two constraints that keep data clean in a relational database. Both appear across SQL and DBMS courses, so students need to know how each one handles uniqueness, NULLs, and indexes.
They look similar, because both prevent duplicate values. Yet they differ in NULL handling, how many a table can have, and their role. This guide defines each, compares them in detail, shows SQL, and clears up two common myths.
They pair closely with another key constraint, so it also helps to know primary key vs foreign key.
What is a Primary Key?
A primary key is a column, or a set of columns, that uniquely identifies each row in a table. So it enforces entity integrity, which means every row is distinct and addressable. Crucially, it allows no NULL values, and a table can have only one.
For example, in an Employees table, the EmployeeID column makes a natural primary key. Other tables then reference it through foreign keys.
Advantages:
- Guarantees a unique, non-NULL identifier for every row.
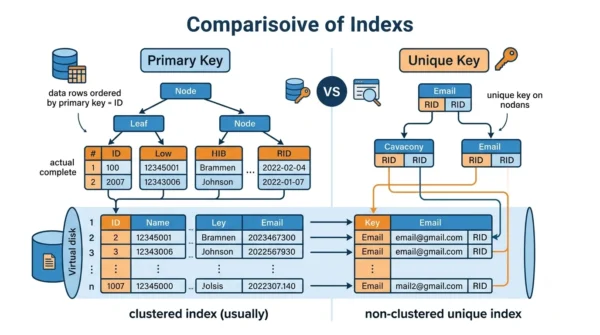
- Usually creates a clustered index, which speeds up lookups.
- Serves as the target for foreign-key relationships.
Disadvantages:
- Only one primary key is allowed per table.
- The index needs some extra storage.
- Choosing a poor key (volatile or wide) can hurt performance.
What is a Unique Key?
A unique key is a constraint that stops duplicate values in a column or set of columns. Unlike a primary key, it allows NULLs, and a table can have several. So it is ideal when an attribute must be unique but not mandatory.
For example, in a Customers table, the Email column suits a unique key, since each email must be unique yet some customers may have none. Note that a unique key still creates an index, as the next section explains.
Advantages:
- Prevents duplicate values in the chosen column(s).
- Allows NULLs, so the attribute can be optional.
- A table can have many unique keys at once.
Disadvantages:
- It is not the row’s main identifier, so it is less central than the primary key.
- NULL behaviour varies by database engine, which can surprise you.
- Too many unique constraints can slow down inserts.
Primary Key vs Unique Key: Comparison Table
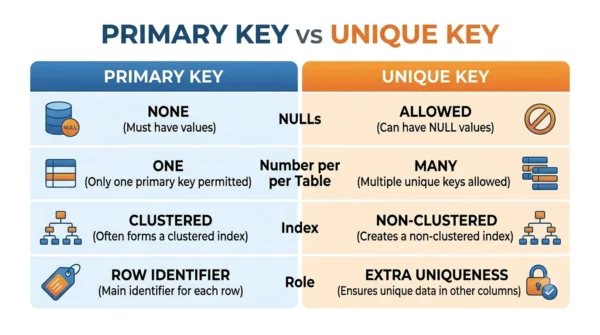
| Aspect | Primary Key | Unique Key |
|---|---|---|
| Purpose | Uniquely identifies each row | Keeps a column’s values unique |
| NULL values | Not allowed | Allowed (one in SQL Server; many in MySQL/PostgreSQL/Oracle) |
| Number per table | Exactly one | Many |
| Index created | Usually a clustered index | A non-clustered unique index |
| Columns | Single or composite | Single or composite |
| Integrity type | Entity integrity | Uniqueness only |
| Foreign-key target | The usual reference | Can also be referenced |
| Relationships | Main way to link tables | Not the default link |
| Mandatory | Implicitly NOT NULL | Optional (can be NULL) |
| When defined | Usually at table creation | At creation or added later |
| Role | The row’s main identifier | An extra uniqueness rule |
| Examples | EmployeeID, OrderID | Email, SSN, Username |
| Typical choice | Often a surrogate ID | Often a natural attribute |
SQL Examples
First, here is a primary key defined when the table is created:
CREATE TABLE Employees (
EmployeeID INT PRIMARY KEY, -- unique, NOT NULL, one per table
Name VARCHAR(50),
Department VARCHAR(50)
);Next, here is a unique key on a column that must be unique but may be optional:
CREATE TABLE Customers (
CustomerID INT PRIMARY KEY,
Name VARCHAR(50),
Email VARCHAR(100) UNIQUE -- unique, but NULLs allowed
);So the primary key is the row’s identity, while the UNIQUE constraint on Email simply blocks duplicates. In both cases the database builds an index behind the scenes.
When to Use a Primary Key or Unique Key
Use a primary key for the one column (or set) that identifies each row, such as an ID. Because other tables link to it through foreign keys, every table should have exactly one.
Use a unique key for any other attribute that must stay unique but is not the main identifier. For example, an email, username, or national ID number fits a unique key, especially when the value can be missing.
In practice, most tables use a surrogate primary key, such as an auto-increment ID, plus one or more unique keys on natural attributes. So the two work together rather than competing.
Frequently Asked Questions
Wrapping Up
Primary keys and unique keys both stop duplicate data, yet they play different roles. A primary key is the one no-NULL identifier for each row, while a unique key adds optional uniqueness on other columns and allows NULLs.
So remember two corrected facts: a unique key does create an index (non-clustered), and it can hold NULLs, with the count depending on the engine. With those clear, you can design tables that stay both unique and well indexed.
Related reading on DiffStudy: