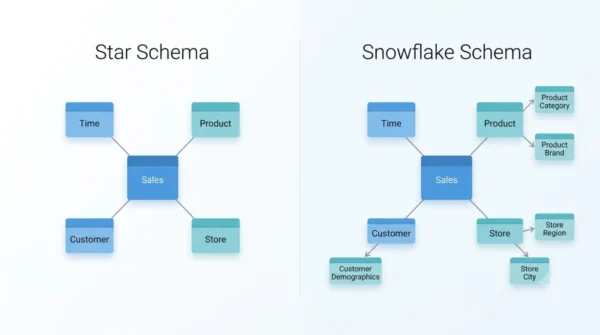
A star schema keeps dimension tables flat and denormalised, so queries need fewer joins and run faster. A snowflake schema normalises those dimensions into smaller related tables, which saves storage and improves data integrity but adds joins. Choose star for fast reporting and choose snowflake for large, tightly structured warehouses.
Data warehouses store huge amounts of business data for analysis and reporting. To keep that data fast to query, designers organise it around fact and dimension tables. The two most common models are the star schema and the snowflake schema.
This guide breaks down the star schema vs snowflake schema debate in plain terms. You will see how each one looks, how it handles normalisation, and how that choice affects query speed and storage.
By the end, you will know exactly which model fits a given workload. The comparison also helps with GATE and database interview questions, so each idea stays short and clear.
What Is a Star Schema?
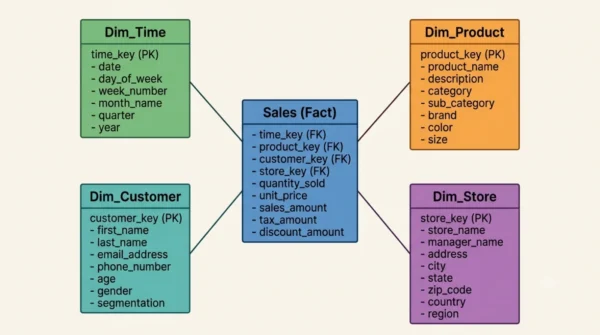
A star schema is a data warehouse model with one central fact table linked to several dimension tables. The fact table holds the numbers you measure, such as sales amount or quantity. The dimension tables hold descriptive context, such as product, time, customer, and store.
Each dimension connects to the fact table with a single key. Because of this, a diagram of the model looks like a star with the fact table in the centre. The dimensions stay denormalised, which means each one is a single flat table.
This flat design makes the model simple to understand and quick to query. As a result, the star schema suits reporting and online analytical processing (OLAP) workloads.
What Is a Snowflake Schema?
A snowflake schema extends the star schema by normalising the dimension tables. In other words, it splits each large dimension into smaller related tables. For example, a Product dimension might break into Product, Category, and Brand tables.
These extra branches form a shape that resembles a snowflake. The fact table still sits in the middle, but the dimensions now spread out through linked sub-tables.
This structure removes repeated values and keeps data tidy. Therefore, it saves storage and protects data integrity. However, queries must join more tables to rebuild the full picture.
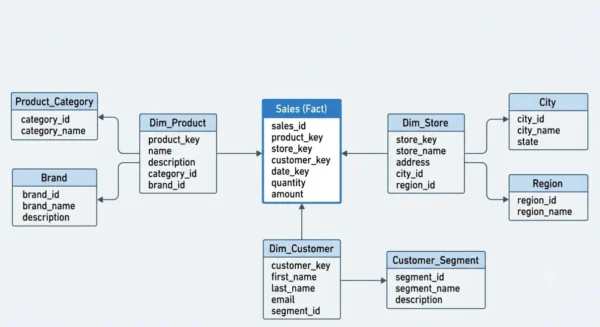
Normalisation: The Core Difference
Normalisation is the heart of the comparison. A star schema keeps dimensions denormalised, so one table holds all attributes for that dimension. A snowflake schema normalises those dimensions into many related tables.
Denormalised tables repeat some values. For instance, the same brand name appears in many product rows. That repetition wastes a little space, yet it removes the need for extra joins.
Normalised tables store each value once in a lookup table. This approach saves space and prevents update problems. To revisit the building blocks behind this idea, the related reading below covers core database design topics.
Query Performance and Joins
Query speed often decides the winner for analysts. A star schema needs fewer joins because each dimension is one table. Fewer joins mean faster reads, which helps dashboards and large aggregations.
A snowflake schema needs more joins to reach the normalised sub-tables. Each extra join adds processing work, so complex queries can run slower. Modern optimisers handle these joins well, yet the star model still wins for simple read-heavy reporting.
Storage tells the opposite story. The snowflake schema removes redundant values, so it usually uses less disk space. The star schema trades some space for speed.
Key Differences at a Glance
The table below sums up the star schema vs snowflake schema comparison across the points that matter most.
| Aspect | Star Schema | Snowflake Schema |
|---|---|---|
| Dimension structure | Denormalised, one flat table per dimension | Normalised into multiple related tables |
| Diagram shape | Star, fact table at the centre | Snowflake, dimensions branch outward |
| Number of tables | Fewer tables | More tables |
| Joins per query | Fewer joins | More joins |
| Query performance | Faster for reads and aggregations | Can be slower on complex queries |
| Storage usage | Higher due to redundancy | Lower due to normalisation |
| Data redundancy | Some repeated values | Minimal repeated values |
| Data integrity | Good, but updates touch more rows | Strong, single source per value |
| Query complexity | Simple to write and read | More complex to write |
| Maintenance and loading | Easier to load | More effort to load and maintain |
| Best fit | Reporting and OLAP dashboards | Large, structured warehouses |
A Quick SQL Example
A short example shows the join difference clearly. In a star schema, you join the fact table straight to flat dimensions.
-- Star schema: fewer joins
SELECT d.brand, t.year, SUM(f.amount) AS total_sales
FROM sales_fact f
JOIN dim_product d ON f.product_key = d.product_key
JOIN dim_time t ON f.time_key = t.time_key
GROUP BY d.brand, t.year;In a snowflake schema, the brand lives in a separate normalised table. So the same report needs one extra join.
-- Snowflake schema: extra join to reach the brand table
SELECT b.brand_name, t.year, SUM(f.amount) AS total_sales
FROM sales_fact f
JOIN dim_product p ON f.product_key = p.product_key
JOIN dim_brand b ON p.brand_key = b.brand_key
JOIN dim_time t ON f.time_key = t.time_key
GROUP BY b.brand_name, t.year;Both queries answer the same business question. The snowflake version simply touches more tables to get there.
When to Use Which
Pick a star schema when read speed and simplicity matter most. It fits business intelligence dashboards, ad hoc reporting, and OLAP cubes. Analysts also write its queries faster because the joins stay shallow.
Pick a snowflake schema when storage and data integrity come first. It suits very large warehouses with many shared attributes and frequent updates. It also helps when dimensions hold deep hierarchies, such as country to region to city.
Many real systems mix both styles. Teams often start with a star schema and normalise only the dimensions that grow too large. This balanced approach keeps reports fast while controlling redundancy.
Interview Questions
FAQ
Wrapping Up
The star schema vs snowflake schema choice comes down to a trade-off. The star schema trades some storage for fast, simple queries. The snowflake schema trades some speed for tidy, normalised data and lower storage use.
Match the model to the workload, not to a rule of thumb. Use a star schema for fast reporting, a snowflake schema for tightly structured warehouses, and a hybrid when you need both.
Related reading on DiffStudy:
- Data Mining vs Data Warehousing
- SQL vs NoSQL Databases
- Clustered vs Non-Clustered Index
- File Systems vs Databases
- DDL vs DML in Database Management
- Structured vs Semi-Structured vs Unstructured Data
- CS Fundamentals