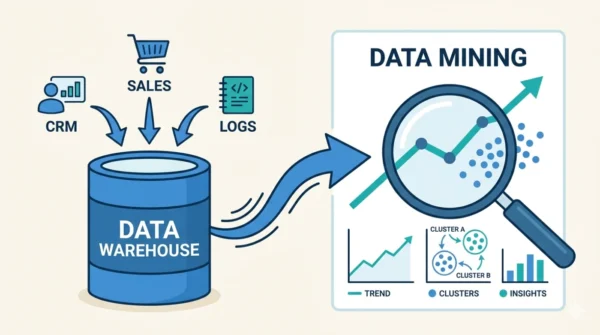
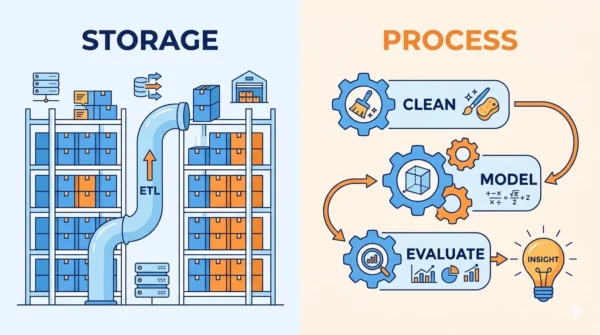
A data warehouse and data mining are not rivals. A data warehouse is a system that stores large amounts of integrated, cleaned data in one place. Data mining is the process of digging through that data to find patterns, trends, and predictions. In short, the warehouse stores; mining analyses.
Many students treat these two terms as opposites, but they actually work as a team. Understanding data mining vs data warehouse the right way helps you answer exam questions and interview prompts with confidence.
One is a place. The other is an activity. The data warehouse is the organised storage that holds your history, while data mining is the workflow that turns that history into useful knowledge.
Below, we break down the purpose, the process versus storage angle, the common techniques and tools, the output of each, and when you would use them. By the end, the difference will feel obvious.
What is a data warehouse?
A data warehouse is a central repository built for analysis and reporting. It collects data from many source systems, such as sales apps, CRM tools, and logs. Then it cleans and integrates that data into one consistent structure.
The goal is a single, trusted version of the truth. Engineers load data through an ETL or ELT pipeline, which stands for Extract, Transform, Load. After loading, the warehouse stores years of historical, subject-oriented data.
Warehouses are optimised for reads, not for fast transactions. They power dashboards, business intelligence reports, and queries that scan huge tables. Popular tools include Snowflake, Amazon Redshift, Google BigQuery, and Microsoft Azure Synapse.
Most warehouses organise data using a star or snowflake schema, with fact tables and dimension tables. This layout keeps analytical queries fast and easy to understand.
What is data mining?
Data mining is the process of discovering useful patterns and relationships hidden inside large datasets. It is an activity, not a storage system. Analysts often run it on data that already lives in a warehouse.
The process applies statistics, machine learning, and pattern recognition to raw or prepared data. As a result, it surfaces trends, clusters, associations, and predictions that humans would miss by eye.
For example, a retailer can mine purchase history to learn which products sell together. A bank can mine transactions to flag likely fraud. These outcomes drive real decisions.
Data mining sits inside a larger workflow often called KDD, or Knowledge Discovery in Databases. That workflow includes selection, preprocessing, transformation, mining, and interpretation.
How they work together
Here is the key idea: these two concepts are complementary, not competing. The warehouse provides clean, integrated, well-organised data. Data mining then uses that data as its raw material.
Think of it like a library and a researcher. The data warehouse is the library that stores and organises every book. Data mining is the researcher who reads across those books to find new insights.
Because the warehouse already cleans and unifies the data, mining becomes faster and more reliable. Without a good warehouse, analysts waste time fixing messy, scattered data first.
Key differences at a glance
The table below sums up the main contrasts. Read it as “storage system versus analysis process”, not as two options that replace each other.
| Aspect | Data Warehouse | Data Mining |
|---|---|---|
| What it is | A storage system or central repository | A process or activity |
| Main purpose | Store and integrate data for analysis | Find patterns, trends, and predictions |
| Core function | Collect, clean, and organise data | Analyse data to extract knowledge |
| Input | Raw data from many source systems | Data already stored, often in a warehouse |
| Output | Organised, query-ready datasets | Insights, models, and rules |
| Data type | Mostly structured, historical data | Structured and unstructured data |
| Typical users | Data engineers and BI teams | Data scientists and analysts |
| Techniques | ETL, schema design, indexing | Clustering, classification, association rules |
| Example tools | Snowflake, Redshift, BigQuery | Python, R, Weka, RapidMiner |
| Time focus | Stores past and present records | Often predicts future outcomes |
| Relationship | Supplies data to mining | Consumes data from the warehouse |
Techniques and tools
Each concept uses its own set of techniques. Knowing them helps you answer pointed exam questions.
Data warehousing relies on ETL pipelines, dimensional modelling, and schema design. Engineers also use indexing, partitioning, and OLAP cubes to speed up queries. Common platforms include Snowflake, Amazon Redshift, Google BigQuery, and Azure Synapse.
Data mining relies on algorithms. The main families include classification, clustering, regression, and association rule mining. Tools and libraries include Python with scikit-learn, R, Weka, RapidMiner, and Apache Spark MLlib.
A simple example shows the contrast clearly. The first query reads from a warehouse, while the second snippet mines patterns from that same data.
-- Data warehouse: a reporting query over stored sales data
SELECT region, SUM(amount) AS total_sales
FROM fact_sales
WHERE sale_year = 2025
GROUP BY region;
# Data mining: clustering customers using Python
from sklearn.cluster import KMeans
model = KMeans(n_clusters=4)
model.fit(customer_features)
segments = model.predict(customer_features)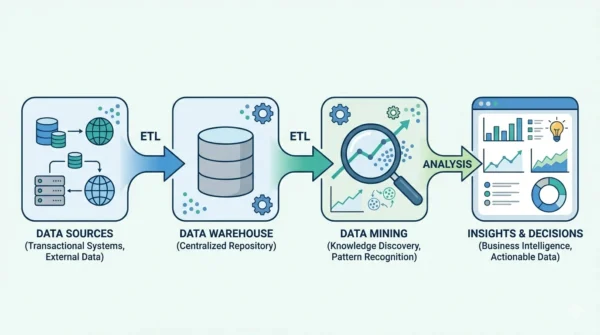
What each one produces
The two concepts deliver very different results. The warehouse produces organised data; mining produces knowledge.
A data warehouse outputs clean, query-ready tables and reports. You run SQL queries and build dashboards on top of it. The output is descriptive and tells you what happened.
Data mining outputs patterns, segments, rules, and predictive models. For example, it might output a model that predicts customer churn. The output is often predictive and tells you what may happen next.
When to use which
Choose based on your goal, since you usually need both at different stages.
Build a data warehouse when you need one trusted place for reporting. It fits cases where data sits in many systems and teams need consistent dashboards. Use it for business intelligence, historical analysis, and standard reports.
Apply data mining when you want to discover something new in that data. It fits fraud detection, customer segmentation, recommendation engines, and forecasting. In practice, you first build the warehouse, then mine the data inside it.
For a typical project, teams set up the warehouse early. After data is clean and centralised, analysts start mining it for deeper insights.
Interview questions
FAQ
Wrapping Up
The cleanest way to remember this topic is one short line. A data warehouse stores integrated data, and data mining finds patterns inside it. They support each other instead of competing.
So when an exam or interview asks you to compare them, lead with that idea. Then add the details on purpose, process versus storage, tools, and output. That structure will set your answer apart.
Related reading on DiffStudy:
- CS Fundamentals
- Star vs Snowflake Schemas
- Structured vs Semi-structured vs Unstructured Data
- SQL vs NoSQL Databases
- Vector Database vs Relational Database
- DDL vs DML in Database Management
- How Data Analytics Is Shaping Industries