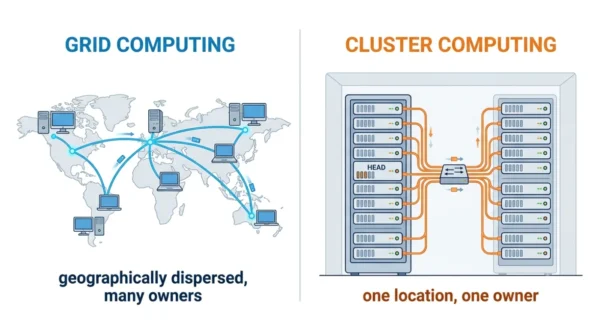
Grid computing links many geographically dispersed, often different computers, owned by several parties, to share resources on big problems. Cluster computing joins similar machines in one location, under one owner, so they act as a single fast system. So a grid is decentralised and spread out, while a cluster is centralised and local. In short, grids favour scale and collaboration, while clusters favour speed and tight control.
Grid and cluster computing are two ways to combine many machines into one powerful resource. Both appear in high-performance and distributed-computing courses, so students need to know how they differ in architecture, location, and control.
The two can look alike, because both pool computers to share a workload. Yet they differ in where the machines sit, who owns them, and how tightly they are coupled. This guide defines each model, compares them in detail, and shows when to use which.
They build on distributed-systems ideas, so it also helps to know distributed vs parallel computing.
What is Grid Computing?
Grid computing connects many computers in different places so they work together on a large problem. Crucially, those machines are often heterogeneous and owned by several organisations, so the grid spans different sites and admin domains. Middleware, such as Globus, ties them together and shares out the work.
Because the resources are decentralised and loosely coupled, a grid scales widely and taps spare capacity from anywhere. For example, volunteer projects like BOINC and SETI@home pool idle home computers worldwide. As a result, grid computing suits big, collaborative jobs that need a vast pool of resources.
Advantages of grid computing:
- Scales across locations, so it gathers huge computational power.
- Uses existing, dispersed resources rather than dedicated hardware.
- Encourages collaboration across organisations.
Disadvantages of grid computing:
- Higher network latency, because resources are geographically spread.
- Harder to secure and coordinate across many owners.
- Needs robust middleware to manage tasks.
What is Cluster Computing?
Cluster computing links several computers, called nodes, in one location so they act as a single system. Usually the nodes are homogeneous and sit under one owner, joined by a fast local network. Therefore they communicate quickly and behave like one powerful machine.
Because the nodes are tightly coupled and close together, a cluster delivers high speed and low latency. So it suits demanding tasks that need quick data exchange, such as HPC and parallel processing. A Beowulf cluster, built from standard PCs on a LAN, is a classic example.
Advantages of cluster computing:
- High speed and low latency, since nodes are local and tightly linked.
- Simpler to manage, because one owner controls the whole cluster.
- Easier to secure with centralised control.
Disadvantages of cluster computing:
- Scales only within one site, so growth is limited.
- Needs dedicated, usually similar hardware.
- A central failure can affect the whole cluster.
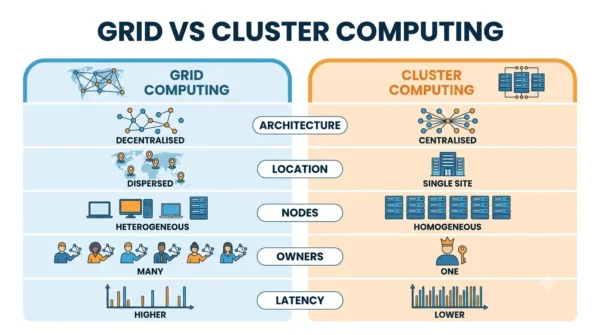
Grid vs Cluster Computing: Comparison Table
| Aspect | Grid Computing | Cluster Computing |
|---|---|---|
| Architecture | Decentralised, distributed | Centralised, single system |
| Location | Geographically dispersed | Single site (one LAN) |
| Coupling | Loosely coupled | Tightly coupled |
| Node hardware | Heterogeneous (varied machines) | Usually homogeneous (similar nodes) |
| Ownership | Many owners / admin domains | One owner / admin domain |
| Communication | Over WAN / internet, higher latency | Fast LAN interconnect, low latency |
| Scalability | Adds resources from anywhere | Adds nodes within one site |
| Resource management | Needs middleware (e.g. Globus) | Centralised scheduler |
| Performance | Wide scale, variable speed | High speed for tight tasks |
| Security | Harder (cross-domain) | Easier (centralised control) |
| Applications | Research, weather, simulations | HPC, data analysis, finance |
| Examples | BOINC, SETI@home, research grids | Beowulf and HPC clusters |
| Setup cost | Uses existing dispersed resources | Dedicated hardware in one place |
Architecture and Scaling
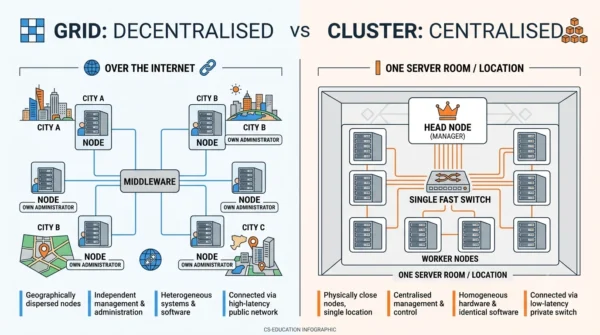
Grid computing uses a decentralised model, so tasks spread across a wide network of independent resources. That model scales organically: as demand grows, the grid pulls in more machines from other locations. However, it also needs strong middleware to allocate work and prevent bottlenecks across so many owners.
Cluster computing instead uses a centralised model, where a head node coordinates identical worker nodes in one place. Because everything is local, a cluster scales by adding more nodes to the same site, which keeps control simple. So management stays centralised and performance stays predictable.
Applications of Grid and Cluster Computing
Each model lands where its strengths fit, so both appear across research and industry.
- Grid in science: scientific research, weather forecasting, and large-scale simulations use grids to tap resources worldwide.
- Grid in collaboration: projects that share data and compute across many institutions rely on a grid’s global reach.
- Cluster in HPC: high-performance computing, parallel processing, and financial modelling use clusters for quick, local data exchange.
- Cluster in services: web-server and database clusters keep applications fast and available within one data centre.
So grids power spread-out, collaborative workloads, while clusters accelerate tight, performance-critical ones.
When to Use Grid or Cluster Computing
Choose grid computing when you need a vast pool of resources from many places, or when several organisations must collaborate. For instance, a global research effort fits the grid model, because it gathers spare capacity wherever it lives.
Choose cluster computing when one organisation needs high performance and low latency in a single location. HPC workloads and parallel jobs suit this model, since the nodes sit close together and exchange data quickly.
In practice, the two can combine. A grid may even link several clusters, so the design gets local speed inside each cluster and global scale across the grid.
Frequently Asked Questions
Wrapping Up
Grid and cluster computing both pool many machines, yet they do it from opposite angles. Grid computing spreads work across dispersed, varied, multi-owner resources for scale, while cluster computing concentrates similar nodes in one place for speed.
Remember the simple rule: grid for wide, collaborative reach, and cluster for fast, local performance. Because real systems often need both, a grid sometimes links several clusters, blending global scale with local speed.
Related reading on DiffStudy: