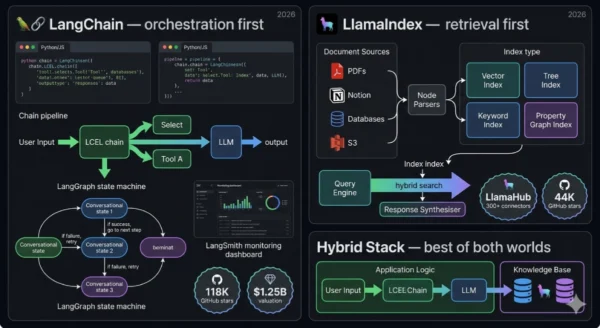
LangChain vs LlamaIndex is the framework decision that every developer building LLM applications faces in 2026 — and the answer has gotten more nuanced, not less. LangChain raised $260 million in total funding, hit a $1.25 billion valuation in October 2025, and now ships four interconnected products: the open-source framework, LangGraph for stateful agent orchestration, LangSmith for observability, and LangServe for deployment.
LlamaIndex, formerly GPT Index, took the opposite bet — going deep on retrieval instead of broad on orchestration, shipping 300+ LlamaHub data connectors, and building hierarchical indexing patterns that produce better RAG quality with 30–40% less code than the equivalent LangChain implementation. Both are open-source, both are production-ready, and both are widely used by teams that have shipped real AI systems. Choosing wrong between them costs you weeks of refactoring. This comparison covers architecture, performance numbers, real production trade-offs, and exactly when to pick each — or when to run them together.
The LLM Framework Landscape in 2026
Two years ago, LangChain and LlamaIndex both did roughly the same thing: they let you connect an LLM to your data. The frameworks have since diverged sharply. LangChain pivoted toward orchestration — building LangGraph to handle stateful multi-step agent workflows, and LangSmith to handle the observability problem that comes with running agents in production. LlamaIndex doubled down on retrieval quality — building better chunking strategies, more index types, and a data connector ecosystem (LlamaHub) that makes document ingestion genuinely fast to ship.
The result is that 2026 teams rarely ask “which is better?” — they ask “what am I primarily building?” If the hard part of your system is connecting an LLM to tools, APIs, and decision loops, LangChain is the right starting point. If the hard part is getting accurate answers out of a large document corpus, LlamaIndex gets you there faster with better retrieval quality out of the box.
LangChain: Orchestration First
LangChain started in late 2022 as a solution to a specific frustration: LLMs could generate text, but they couldn’t search the web, call APIs, or interact with databases. Harrison Chase built the first version as a side project and released it publicly. Within months it became one of the fastest-growing open-source projects in GitHub history, hitting 10,000 stars in March 2023 and 90,000 by June 2024. The appeal was immediate — LangChain gave developers a modular set of building blocks for wiring LLMs to external tools, creating a “composability” layer that the raw model APIs lacked.
By 2026, LangChain has evolved into a four-product platform. The core open-source framework provides chains, agents, prompts, and memory abstractions — over 500 integrations with model providers, vector databases, and APIs. LangGraph is the newer orchestration layer that represents the company’s strategic bet: stateful agent workflows modelled as directed graphs, where Python functions are nodes, typed state flows between them, and cycles enable self-correction loops that flat chain architectures cannot express. LangSmith is the commercial monitoring and evaluation product — the main revenue driver, with ARR between $12 million and $16 million as of mid-2025. LangServe converts any LangChain application into a deployed API in a single line.
Where LangChain Wins
- Complex agent workflows: LangGraph’s stateful graph model handles the kinds of agents that need to loop, branch conditionally, pause for human input, and self-correct — patterns that flat chain architectures cannot express cleanly
- Multi-tool orchestration: When your agent needs to decide between a database query, a web search, a calculator, and a code interpreter based on context, LangChain’s tool-calling abstractions manage this decision logic more naturally than LlamaIndex’s workflow system
- Breadth of integrations: 500+ supported integrations — model providers, vector stores, databases, APIs — means less custom glue code when connecting components that aren’t yet natively supported by LlamaIndex
- Conversation memory: LangChain’s memory management is designed for long, stateful conversations that must maintain context across many turns — a use case where LlamaIndex’s more limited context retention shows its seams
- LangSmith observability: If you need to understand why your agent did what it did, trace costs across LLM calls, evaluate outputs systematically, and annotate datasets for fine-tuning — LangSmith is the most capable production observability tool in this space
- Multimodal workflows: LangChain’s media support covers video, audio, images, and PDFs alongside APIs — broader than LlamaIndex’s primarily text and document focus
The Real Trade-offs
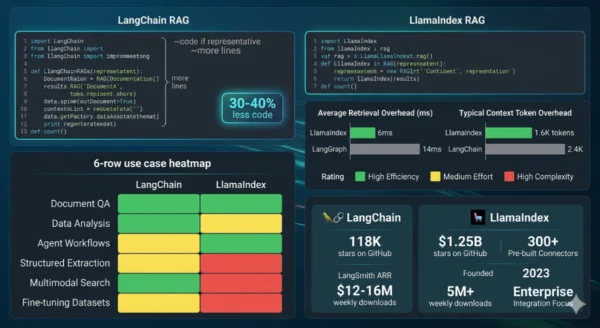
- More code for RAG: For a standard document retrieval pipeline, LangChain requires assembling text splitter + embedding model + vector store + retriever + chain separately — typically 30–40% more code than the equivalent LlamaIndex implementation
- Deep stack traces when things break: LangChain’s abstraction layers are a double-edged sword — they save code in the happy path but make debugging painful when something breaks. Stack traces are deep, error messages are generic, and reasoning through multiple abstraction layers takes time
- API instability history: LangChain went through significant API churn around v0.1/v0.2 that burned production teams who had not pinned versions carefully. Stability has improved, but pinning versions and reviewing changelogs before upgrades remains non-optional
- Higher framework overhead: LangGraph adds approximately 14ms per request compared to LlamaIndex’s 6ms — invisible at low volume, material at 100+ concurrent users
- Community integration quality varies: The breadth of 500+ integrations is real, but many community-contributed connectors are poorly maintained and break silently when upstream services change
LangChain at a Glance (2026):
GitHub: 118,000+ stars, 18,000+ forks. Downloads: 5M+ weekly PyPI downloads, 100M+ cumulative. Funding: $260M total — seed $10M (Benchmark), Series A $25M (Sequoia), Series B $125M (IVP) at $1.25B valuation. Commercial: LangSmith ARR $12–16M; customers include Klarna, Rippling, Replit. Furthermore, Products: LangChain framework (open-source), LangGraph (agent orchestration), LangSmith (observability), LangServe (deployment). Integrations: 500+ with model providers, vector databases, tools, and APIs. Framework overhead: ~14ms (LangGraph), ~2.4K tokens per request.
LlamaIndex: Retrieval First
LlamaIndex was released in late 2022 as GPT Index — a tool for connecting language models to documents. It was renamed LlamaIndex in 2023 and has since built an identity around a clear thesis: the bottleneck in most production LLM applications is not the model or the orchestration, it’s the retrieval. Getting the right chunks of the right documents into the model’s context window, ranked correctly, without hallucinated references, is the hard engineering problem. LlamaIndex is purpose-built to solve it.
Where LangChain’s retrieval component is one of many building blocks you assemble, LlamaIndex’s retrieval is the whole story. The framework ships multiple index types — vector indices for semantic search, tree indices for hierarchical documents, keyword indices for exact-match retrieval, and the newer Property Graph Index for structured knowledge — each optimised for different data shapes and query patterns. LlamaHub provides 300+ data connectors specifically designed for document ingestion: not generic API clients, but connectors built to handle the edge cases of ingesting Notion pages, Google Drive documents, Confluence wikis, and database rows into a consistent chunked format. Advanced retrieval patterns — hierarchical chunking, auto-merging retrieval, sub-question decomposition, hybrid search combining vector and keyword — are available out of the box, not as custom assembly jobs.
Where LlamaIndex Wins
- RAG quality out of the box: Hierarchical chunking, auto-merging retrieval, and sub-question decomposition produce better retrieval accuracy than LangChain’s component-based approach — more relevant context in the model’s window with less tuning required
- Less code for document pipelines: The higher-level abstractions (data connectors → node parsers → indices → query engines) map directly onto what most RAG applications need — 30–40% less code than equivalent LangChain implementations, which compounds when you iterate on chunking strategies
- LlamaHub connectors are document-aware: 300+ connectors specifically optimised for document ingestion — handling the pagination quirks of Notion’s API, the nested structure of Confluence spaces, the binary encoding of PDFs — not generic REST clients repurposed for documents
- Lower latency and token overhead: Approximately 6ms framework overhead versus LangGraph’s 14ms; approximately 1.6K token overhead versus 2.4K — these differences compound across high-volume production deployments
- Structured data extraction: PropertyGraphIndex and structured extraction tools for pulling structured data out of unstructured documents — a use case where LlamaIndex outperforms what you’d assemble manually with LangChain
- Cleaner upgrade path: LlamaIndex has a better track record of stable releases than LangChain’s earlier versions — teams that have been burned by framework churn report fewer painful upgrades on the LlamaIndex side
The Real Trade-offs
- Steeper initial learning curve: LlamaIndex’s conceptual model — nodes, indices, query engines, postprocessors, response synthesisers — takes longer to internalise than LangChain’s chain/agent model. The first day with LlamaIndex is harder than the first day with LangChain
- Weaker for complex agent workflows: LlamaIndex has added agents and workflow primitives, but they are not as mature as LangGraph for complex stateful reasoning, multi-step tool selection, and loop-with-correction patterns. The framework’s identity is still retrieval, not orchestration
- Fewer integrations overall: 300+ LlamaHub connectors versus LangChain’s 500+ overall integrations — LlamaIndex wins on document-specific connectors, loses on breadth of tool and model integrations for agentic use cases
- No equivalent to LangSmith: LlamaIndex lacks a commercial observability product as mature as LangSmith — teams running LlamaIndex in production typically pair it with third-party observability tooling or LangSmith itself
- Less flexible for non-RAG use cases: LlamaIndex is excellent when your problem is “get accurate answers from documents.” When your problem is something else — a chatbot with complex tool use, a workflow automation agent, a multi-modal reasoning system — LlamaIndex’s prepackaged abstractions can feel constraining
LlamaIndex at a Glance (2026):
GitHub: 44,000+ stars. Founded: 2022 (released as GPT Index), renamed LlamaIndex 2023. Data connectors: 300+ via LlamaHub — Notion, Google Drive, Confluence, S3, databases, PDFs, APIs. Index types: Vector Index (semantic), Tree Index (hierarchical), Keyword Index (exact match), Property Graph Index (structured knowledge). Furthermore, Advanced retrieval: Hierarchical chunking, auto-merging retrieval, sub-question decomposition, hybrid search (vector + keyword). Framework overhead: ~6ms, ~1.6K tokens per request. Code efficiency: 30–40% less code than LangChain for equivalent RAG pipelines.
Architecture and Performance Deep Dive
The architectural difference between LangChain and LlamaIndex is the difference between a general-purpose operating system and a database engine. Both let you store and retrieve data. The database engine does it faster, with better query optimisation, and with less configuration required — but it cannot run your word processor.
How LangChain Builds a RAG Pipeline
LangChain approaches RAG as an assembly task. You select a text splitter, configure chunk size and overlap, choose an embedding model, pick a vector store, instantiate a retriever, wire it to an LLM via LangChain Expression Language (LCEL), and define the prompt template. Each component is interchangeable — you can swap OpenAI embeddings for Cohere, Chroma for Pinecone — and the assembly gives you explicit control over every stage. This is genuinely valuable when your retrieval pipeline does not fit standard patterns. It is overhead when it does.
LangGraph extends this with a graph-based state machine. You define nodes as Python functions, edges as transitions between them (including conditional routing based on state), and a central TypedDict or Pydantic model as the shared state object. Built-in checkpointers save state to SQLite, PostgreSQL, or Redis for human-in-the-loop patterns and recovery. Native cycle support enables self-correction loops — an agent that evaluates its own output and retries if the quality is insufficient. This is the architectural pattern that most serious agent applications require, and LangGraph is currently the best open-source implementation of it.
How LlamaIndex Builds a RAG Pipeline
LlamaIndex approaches RAG as a purpose-built pipeline with sensible defaults at every stage. You point it at your data sources (LlamaHub handles the ingestion quirks), it parses documents into nodes, you choose an index type based on your query patterns, and the query engine handles retrieval, ranking, and response synthesis. The same pipeline that would require 100 lines in LangChain often ships in 40–60 lines with LlamaIndex because the higher-level abstractions assume you are building a document retrieval system.
The retrieval quality improvement comes from LlamaIndex’s more sophisticated default strategies. Hierarchical chunking stores both a full document and its individual paragraphs, retrieving the granular chunk for ranking but passing the parent document to the model for context — preserving semantic coherence that naive chunking destroys. Auto-merging retrieval detects when multiple granular chunks from the same parent document are retrieved and replaces them with the parent, reducing noise. Sub-question decomposition breaks complex queries into simpler sub-questions, retrieves answers to each, and synthesises a response — enabling multi-hop reasoning that single-query retrieval cannot do.
Performance Numbers That Matter in Production
| Metric | LangChain / LangGraph | LlamaIndex | When It Matters |
|---|---|---|---|
| Framework overhead (latency) | ~14ms per request | ~6ms per request | High-concurrency production (100+ simultaneous users) |
| Token overhead per request | ~2.4K tokens | ~1.6K tokens | Cost-sensitive deployments; compounds at scale |
| Code volume for equivalent RAG | Baseline (more code) | 30–40% less code | Speed of iteration; maintenance burden |
| RAG retrieval quality (standard corpora) | Good with tuning | Better out-of-the-box | When retrieval accuracy is the primary success metric |
| Agent complexity ceiling | High — LangGraph handles cycles, conditional edges, human-in-loop | Moderate — Workflows support branching, parallel execution | Complex multi-step reasoning, self-correction loops |
| Integration breadth | 500+ integrations | 300+ (LlamaHub, document-focused) | Connecting to tools and APIs beyond document retrieval |
Code Comparison: The Same RAG Pipeline in Both Frameworks
The 30–40% code difference is not abstract. Here is what a basic document Q&A pipeline looks like in both frameworks. Both produce functionally equivalent results against the same document — LlamaIndex gets there in fewer decisions and less boilerplate.
LangChain RAG (simplified)
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain_community.vectorstores import Chroma
from langchain.chains import RetrievalQA
# Load and split
loader = PyPDFLoader("document.pdf")
docs = loader.load()
splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, chunk_overlap=200
)
chunks = splitter.split_documents(docs)
# Embed and store
embeddings = OpenAIEmbeddings()
vectorstore = Chroma.from_documents(chunks, embeddings)
retriever = vectorstore.as_retriever(
search_kwargs={"k": 4}
)
# Chain
llm = ChatOpenAI(model="gpt-4o")
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=retriever,
return_source_documents=True
)
result = qa_chain.invoke({"query": "What is the main finding?"})
print(result["result"])~25 lines — more decisions, more flexibility
LlamaIndex RAG (simplified)
from llama_index.core import (
VectorStoreIndex,
SimpleDirectoryReader
)
from llama_index.llms.openai import OpenAI
# Load
documents = SimpleDirectoryReader(
input_files=["document.pdf"]
).load_data()
# Index (handles chunking and embedding)
index = VectorStoreIndex.from_documents(documents)
# Query engine (handles retrieval and synthesis)
query_engine = index.as_query_engine(
llm=OpenAI(model="gpt-4o"),
similarity_top_k=4
)
response = query_engine.query(
"What is the main finding?"
)
print(response)~15 lines — fewer decisions, faster to ship
The code difference scales as your pipeline grows in complexity. When you add hybrid search, re-ranking, and sub-question decomposition to a LlamaIndex pipeline, you add a few configuration parameters. Adding equivalent functionality to a LangChain pipeline requires importing additional components, writing adapter code, and managing more state. Neither approach is wrong — but LlamaIndex’s compounding code savings matter in teams that iterate rapidly on retrieval strategy.
12 Critical Differences: LangChain vs LlamaIndex
Aspect | LangChain | LlamaIndex |
|---|---|---|
| Core Philosophy | Orchestration — wire LLMs, tools, memory, and APIs into composable multi-step workflows | Retrieval — ingest documents, build indices, and serve high-quality answers from your data |
| Primary Use Case | Complex agent systems with tool use, memory, conditional logic, and multi-step reasoning | RAG pipelines, document Q&A, knowledge bases, and enterprise search over private data |
| Code Volume (RAG) | More — requires assembling each component (loader, splitter, embedder, store, retriever, chain) | 30–40% less — higher-level abstractions map directly to document retrieval patterns |
| Framework Overhead | ~14ms per request (LangGraph); ~2.4K tokens overhead | ~6ms per request; ~1.6K tokens overhead — lighter footprint at scale |
| Agent Capability | Excellent — LangGraph provides stateful graphs, cycles, conditional edges, checkpointing, human-in-the-loop | Good — Workflows support branching and parallel execution; not as mature as LangGraph for complex loops |
| RAG Quality | Good with tuning — requires manual selection of chunking strategy, retrieval algorithm, re-ranking | Better out of the box — hierarchical chunking, auto-merging, sub-question decomposition as defaults |
| Data Connectors | 500+ integrations — broad but variable quality; many community-maintained connectors | 300+ LlamaHub connectors — fewer but document-optimised; built for ingestion quality not just connection |
| Memory / State | Excellent — multiple memory types (buffer, summary, entity, knowledge graph); designed for long conversations | Basic — suitable for document context retention; not designed for multi-turn conversation memory |
| Observability | LangSmith — commercial product, best-in-class for LLM tracing, evaluation, and annotation | No native equivalent; integrates with third-party tools (Arize, Weights & Biases, LangSmith) |
| Learning Curve | Faster initial start — chain/agent mental model is intuitive; debugging depth is the challenge | Steeper initial start — nodes/indices/query engines take time to internalise; cleaner once understood |
| GitHub Stars / Community | 118,000+ stars; 50,000+ Discord; massive ecosystem; framework of record for LLM development | 44,000+ stars; strong community; recognised as the specialist retrieval framework |
| Commercial Backing | $260M raised; $1.25B valuation; LangSmith ARR $12–16M; Sequoia, Benchmark, IVP backing | VC-backed but smaller raise; enterprise focus through LlamaCloud and LlamaParse products |
Use Cases and Team Profiles
The most useful framing is not “LangChain or LlamaIndex” but “what is the hard part of my application?” If retrieval quality is the hard part, start with LlamaIndex. If agent orchestration is the hard part, start with LangChain. Most applications that start with one framework eventually encounter the other’s problem — which is why production stacks increasingly use both.
Start with LangChain If:
- You’re building an agent that selects between multiple tools, maintains conversation state across turns, and needs to loop and self-correct — LangGraph is the right primitive for this
- Your application is more workflow than retrieval — customer service agents, code generation assistants, research agents that browse the web and synthesise findings
- You need multimodal input handling — LangChain’s media support covers video, audio, images, and complex API responses that LlamaIndex’s document focus does not handle as cleanly
- You want LangSmith — if production observability, systematic evaluation, and human annotation workflows are priorities from day one, LangSmith’s integration with the LangChain ecosystem is its strongest argument
- Your team is Python-first and wants maximum control — LangChain’s component assembly model rewards developers who want to understand and control every step of the pipeline
Start with LlamaIndex If:
- You’re building document Q&A — internal knowledge bases, customer-facing document search, contract analysis, research assistants that answer questions from a corpus
- Retrieval quality is your primary success metric — if the difference between “finds the right passage” and “returns adjacent text” matters to your users, LlamaIndex’s advanced retrieval strategies get you there with less tuning
- You want to ship a working RAG prototype fast — the higher-level abstractions mean fewer decisions before your first working demo; iterate on chunking and retrieval strategy after you’ve validated the use case
- Your data is document-heavy and heterogeneous — PDFs, Notion pages, Confluence wikis, database rows, web pages — LlamaHub’s document-aware connectors handle the ingestion edge cases that generic loaders miss
- You have hierarchical or structured documents — technical manuals, legal contracts, financial reports where preserving document structure in retrieval matters
The Production Hybrid Stack
The pattern that has emerged in mature production deployments combines both frameworks by layer. LlamaIndex handles everything from raw documents to retrieved context — ingestion, chunking, indexing, retrieval, re-ranking. LangGraph receives that context and handles what to do with it — routing between tools, managing state, executing multi-step plans. LangSmith sits above both, tracing every LLM call across the combined stack.
Example architecture: An enterprise knowledge assistant that answers questions from 50,000 internal documents and can also search the web, query a database, and escalate to a human reviewer when confidence is low.
- LlamaIndex: Ingests and indexes all 50,000 documents; handles incoming user query through hierarchical retrieval; returns top-k passages with confidence scores
- LangGraph: Receives query and retrieved context; decides whether the retrieved context is sufficient or whether the agent should also search the web, query the database, or ask a clarifying question; manages the state of the multi-turn interaction
- LangSmith: Traces every LLM call, logs retrieval quality metrics, enables evaluation of whether the final answer was correct
Ecosystem, Pricing and Market Data
Both frameworks are open-source with permissive licences (MIT). The cost comparison is about ecosystem maturity, commercial products, and at-scale operational costs rather than licence fees.
LangChain Valuation
$1.25B
October 2025 Series B; $260M total raised from Sequoia, Benchmark, IVP, CapitalG
LangChain Stars
118K+
GitHub stars; 5M+ weekly PyPI downloads; the most-downloaded LLM framework
LlamaHub Connectors
300+
Document-optimised data connectors covering every major enterprise data source
LangSmith ARR
$12–16M
LangSmith commercial observability product ARR as of mid-2025
LangSmith Pricing (the main commercial component)
| Tier | Price | Includes | Best For |
|---|---|---|---|
| Developer | Free | 14-day trace retention, 5K traces/month, 1 workspace | Individual developers building and debugging locally |
| Plus | $39/month | 90-day retention, 50K traces/month, team collaboration, annotation queues | Small teams shipping to production who need shared evaluation |
| Enterprise | Custom | Custom retention, unlimited traces, SSO, audit logs, dedicated support | Organisations running agents at scale; Klarna, Rippling, Replit model |
LlamaCloud and LlamaParse (LlamaIndex commercial products)
LlamaIndex has launched two commercial products alongside the open-source framework. LlamaParse is a document parsing API that handles complex PDFs, tables, charts, and mixed-format documents more accurately than open-source alternatives — with usage-based pricing starting free and scaling with document volume. LlamaCloud is a managed indexing and retrieval infrastructure for teams that want LlamaIndex’s retrieval quality without managing their own vector database and indexing pipeline. Both are in active development and pricing is evolving — check LlamaIndex’s current documentation for current tiers.
At-Scale Cost Considerations
At low request volumes, the performance differences between LangChain and LlamaIndex are invisible. At 1,000+ daily active users running LLM-powered applications, the numbers matter. LlamaIndex’s approximately 800-token reduction in per-request overhead (1.6K vs 2.4K) translates directly to LLM API costs — at $5/million tokens (GPT-4o pricing), 800 tokens per request across 10,000 daily queries costs an additional $4/day, or approximately $1,500/year, just in framework overhead tokens. At 100,000 daily queries, that gap is $15,000/year. These numbers justify the retrieval-first approach for cost-sensitive high-volume deployments even if the engineering team is more familiar with LangChain.
Decision Framework
The One Question That Determines Your Choice
Is the hard part of your application getting the right information into the model’s context window, or is it deciding what to do with information across multiple steps? Retrieval-hard → start with LlamaIndex. Orchestration-hard → start with LangChain. Both-hard → start with LlamaIndex for retrieval, add LangGraph for orchestration, monitor both with LangSmith.
Choose LangChain When:
- Your primary output is an agent that reasons, selects tools, and takes actions — not a document that answers questions
- You need LangSmith’s observability from day one — systematic evaluation and production tracing are non-negotiable for your deployment
- Your data sources include live APIs, web content, databases, and multimedia — not primarily static documents
- You need complex conversation memory across 10+ turns — LangChain’s memory abstractions handle this; LlamaIndex does not
- Your team has already built with LangChain and the retrieval quality is acceptable — switching costs outweigh the retrieval improvement
- You are building a prototype of something complex and need the widest possible integration surface before you know exactly what you’ll connect to
Choose LlamaIndex When:
- Your application is a knowledge assistant, document Q&A system, or enterprise search — the retrieval problem is the core engineering challenge
- Retrieval accuracy is your primary success metric — users notice when the answer comes from the wrong passage, and you need the best retrieval defaults available
- Speed to first working demo matters — LlamaIndex’s abstractions get a document Q&A system to a working demo in fewer decisions
- You are working with hierarchical, structured, or heterogeneous document types where preserving document structure in retrieval matters
- Cost and latency at scale are constraints — the 30–40% code reduction and lower token/latency overhead compound meaningfully at production volume
- You can pair LlamaIndex with LangSmith for observability — you do not need to use LangChain’s full stack to use its best commercial product
Quick Decision Table
| You’re building… | Start with | Why |
|---|---|---|
| Customer support agent with 5 tools | LangChain (LangGraph) | Tool routing, memory, conditional loops — orchestration is the hard part |
| Internal knowledge base Q&A (10K docs) | LlamaIndex | Retrieval quality is the hard part; less code to ship |
| Legal contract analysis system | LlamaIndex | Document structure matters; hierarchical chunking preserves context |
| Research agent that browses web + cites sources | LangChain | Multi-step web search + synthesis is orchestration, not retrieval |
| Enterprise search across 50K documents + tools | Both (hybrid) | LlamaIndex for retrieval layer, LangGraph for decision layer |
| RAG prototype to validate a product idea | LlamaIndex | 30–40% less code; faster to first demo and iteration |
| Chatbot with 20-turn memory requirement | LangChain | Sophisticated memory management is LangChain’s strength |
| Code generation assistant (like Copilot) | LangChain | Tool use (interpreter, linter, file system) + loops is orchestration |
| PDF ingestion + question answering product | LlamaIndex + LlamaParse | LlamaParse for complex PDF parsing; LlamaIndex for retrieval |
| Any production deployment needing monitoring | Add LangSmith | Works with both frameworks; best LLM observability available |
Frequently Asked Questions
Hierarchical chunking is one of LlamaIndex’s key retrieval strategies that addresses a fundamental problem with naive text chunking: small chunks rank well in similarity search but lose context; large chunks have full context but rank poorly and consume too many tokens. LlamaIndex’s hierarchical approach stores documents at two levels simultaneously — granular child nodes (individual paragraphs or sentences) for precise similarity matching, and larger parent nodes (full sections or pages) for contextual completeness.
During retrieval, the query is matched against the granular child nodes to find the most precisely relevant passages. When a child node is retrieved, LlamaIndex automatically fetches its parent node to provide the model with the surrounding context rather than an isolated sentence fragment. The model receives the semantically relevant passage plus its full document context, improving answer quality without the retrieval noise that comes from matching against large document blocks. Auto-merging retrieval extends this further: when multiple child nodes from the same parent are retrieved, LlamaIndex merges them back into the parent node before passing to the model, reducing redundancy and improving coherence.
LlamaHub is LlamaIndex’s open-source repository of 300+ data connectors for ingesting documents from virtually every enterprise data source: Notion pages, Google Drive documents, Confluence wikis, Slack channels, databases (PostgreSQL, MySQL, MongoDB), cloud storage (S3, GCS), web pages, PDFs, Word documents, Excel files, and more.
The key difference from LangChain’s connectors is optimisation focus: LlamaHub connectors are specifically built for document ingestion quality — they handle the quirks of Notion’s block API structure, the pagination patterns of Confluence spaces, the nested hierarchy of file systems — not as generic REST clients, but as document-aware loaders that produce clean, well-structured nodes for indexing. LangChain’s 500+ integrations cover a broader surface (including real-time data sources, action-taking tool connectors, and non-document APIs) but the individual connectors are not uniformly optimised for retrieval quality. If your primary data source is enterprise documents and you need to ingest them reliably at scale, LlamaHub’s connectors produce cleaner nodes with less custom preprocessing work. If you need to connect to live data sources, take actions via APIs, or integrate with tools beyond document retrieval, LangChain’s broader ecosystem is the right choice.
For most beginners, LangChain is the more accessible starting point because its chain/agent mental model is intuitive and closely matches how developers already think about function composition and API calls. The concept of “call this LLM with this prompt, then pass the output to this function” maps naturally onto LangChain’s architecture.
The ecosystem is also larger — more tutorials, more Stack Overflow answers, more example repositories. That said, LlamaIndex is the better first framework if you know in advance that you are building document retrieval — starting with the right tool for your specific use case is more valuable than starting with the most popular tool. The practical recommendation: learn LangChain’s core concepts first (chains, agents, prompts, memory), then learn LlamaIndex’s retrieval primitives (indices, query engines, node parsers) when you need to build a document-heavy application. LangGraph is worth learning third, once you understand the basics of agent design well enough to appreciate why a stateful graph model is superior to flat chains for complex agents.
Multi-agent systems — where multiple specialised AI agents collaborate on a shared task — are increasingly the architecture of choice for complex applications in 2026, and both frameworks have invested here. LangGraph is currently the stronger foundation for multi-agent systems. Its graph model naturally extends to multiple agents: each agent is a subgraph, shared state flows between them, and the supervisor agent routes tasks based on output quality or specialisation.
The checkpointing and human-in-the-loop features of LangGraph make it practical to deploy multi-agent systems where human review is required at specific decision points — a common enterprise requirement. LlamaIndex’s Workflows feature supports concurrent, event-driven execution of multiple pipeline steps and can coordinate multiple specialised query engines. For multi-agent document research tasks — where Agent A retrieves from a financial database, Agent B retrieves from a legal corpus, and a synthesiser agent combines their findings — LlamaIndex Workflows is a natural fit. For general-purpose multi-agent coordination where agents have different tools and capabilities rather than different retrieval sources, LangGraph provides a more mature orchestration primitive. Many teams building sophisticated multi-agent systems in 2026 use LangGraph for agent coordination and LlamaIndex for the retrieval tools those agents call.
The LLM framework landscape has grown substantially since LangChain and LlamaIndex launched. In the orchestration space (LangChain’s domain), Microsoft Semantic Kernel targets Azure-centric enterprises with a compliance-first design. OpenAI’s Agents SDK tightly integrates with GPT models and reduces third-party dependency for teams committed to the OpenAI ecosystem. Meanwhile, CrewAI specialises in multi-agent role-based coordination and often outperforms LangChain for crew-style orchestration patterns. At the autonomous end of the spectrum, AutoGPT and similar agents focus on self-directed workflows.
Shifting to retrieval (LlamaIndex’s domain), Haystack (by deepset) stands out as the most direct competitor, with strong enterprise adoption particularly in Europe. A different paradigm is introduced by DSPy from Stanford, which learns optimal prompts and retrieval strategies automatically instead of relying on manual design. In the observability layer (LangSmith’s space), Langfuse and Helicone provide open-source alternatives at a lower price point. For teams needing more advanced ML monitoring, Arize and Weights & Biases offer robust solutions. Overall, LangChain and LlamaIndex remain the most widely used general-purpose options in 2026, but the “best framework” increasingly depends on your specific use case, model provider, and cloud infrastructure rather than a simple capability comparison.
Final Verdict
The LangChain vs LlamaIndex decision is simpler than most comparisons make it. LangChain is the framework for when your agent needs to do things — reason across tools, maintain state, coordinate between capabilities. LlamaIndex is the framework for when your application needs to know things — accurately retrieve relevant information from your documents and data sources with the least code and best quality.
LangChain — The Numbers:
- 118,000+ GitHub stars; $260M raised; $1.25B valuation
- 5M+ weekly PyPI downloads; 200+ Fortune 500 users
- LangSmith: $12–16M ARR; best LLM observability available
- LangGraph: stateful agents with cycles, human-in-the-loop
- ~14ms overhead, ~2.4K tokens; 500+ integrations
- Best for orchestration, complex agents, multimodal, memory
LlamaIndex — The Numbers:
- 44,000+ GitHub stars; 300+ LlamaHub document connectors
- 30–40% less code for equivalent RAG pipelines
- ~6ms overhead, ~1.6K tokens — lighter at scale
- Hierarchical chunking, auto-merging, sub-question decomposition
- LlamaParse + LlamaCloud for complex document needs
- Best for RAG, document Q&A, enterprise search, knowledge bases
Practical starting point for 2026:
If you are building a document Q&A system, start with LlamaIndex — you’ll ship faster and get better retrieval quality. Add LangGraph when your application needs the agent to do more than retrieve. Add LangSmith to both, regardless of which framework you use underneath — it’s the best production monitoring tool available and you’ll want it before you go live. If you are building an agent that uses tools, connects to live data, and maintains conversation state, start with LangGraph and wire in LlamaIndex as a retrieval tool when you need document knowledge. Most real applications eventually need both halves of this stack.
Related Topics Worth Exploring
RAG vs Fine-tuning
LangChain and LlamaIndex both build RAG systems — but when should you retrieve instead of fine-tune? The decision between keeping knowledge external (RAG via LlamaIndex) versus baking it into model weights (fine-tuning) is foundational to every LLM application design. Understanding this trade-off determines whether you need either framework at all.
Vector Database vs Relational Database
Both LangChain and LlamaIndex store their document embeddings in vector databases — the retrieval layer underneath every RAG pipeline. Choosing between Pinecone, Weaviate, Chroma, pgvector, and others involves the same architectural trade-offs as choosing your LLM framework: flexibility vs simplicity, self-hosted vs managed, speed vs cost.
AI Agents vs RPA
LangGraph (LangChain’s agent layer) is one of the primary platforms for building the AI agents that are replacing traditional RPA in enterprise automation. Understanding what makes an LLM-based agent fundamentally different from a rule-based bot — and when each approach is actually appropriate — frames the orchestration-vs-retrieval debate in its business context.